머신러닝 독학 과정, 후기 및 미니 프로젝트
by 나다경
Chapter1. 머신러닝 독학 과정, 후기
1.1 머신러닝이란?

데이터를 기반으로 패턴을 학습하고 결과를 예측하는 알고리즘 기법을 통칭함
머신러닝 알고리즘은 데이터를 기반으로 통계적인 신뢰도를 강화하고 예측 오류를 최소화하기 위한 다양한 수학적 기법을 적용해 데이터 내의 패턴을 스스로 인지하고 신뢰도 있는 예측 결과를 도출해 냄
데이터 분석 영역은 재빠르게 머신러닝 기반의 예측 분석으로 재편되고 있음
ex. 데이터마이닝, 영상 인식, 음성 인식, 자연어 처리 등
1.2 CS109
학습 순서
-
이 코스는 매우 기본적인 Python, Pandas를 다루는 과정부터 Probability, Distributions(Frequentist Statistics), Regression, Logistic Regression와 같은 통계적인 개념, Machine Learning, Ensembles, Bayes, Text and Clustering, Deep Networks까지 전반적인 내용을 다루고 있음
-
통계학 베이스가 있기 때문에 Week5의 Regression부터 수강함
-
Week5 Regression, Logistic Regression: in sklearn and statsmodels ~ Week11 Text and Clustering까지
학습 소요 시간 하루에 강의 1개씩, 약 1달
학습 방법
영상 + 자막 -> git에 있는 학습 자료바탕 + 필기
학습 소감
수학적 개념을 깊게 다루지 않고 기본적인 머신러닝 개념 위주로 다뤄서 내용은 이해하기에 어렵지 않았음. 처음 입문하기에는 나쁘지 않은 강의라고 볼 수 있음.
-
장점
-
질 높은 하버드 강의를 무료로 들을 수 있음
-
머신러닝을 체계적으로 공부할 수 있음. 몰아서 들으니깐 계절학기 느낌으로다가 수강 가능
-
-
단점
- 영어 강의이기에 한국어보다는 확실히 이해가 힘듦
- 깊은 수학적 지식을 다루지 않아서 이미 공부한 사람들에게는 적합하지 않을 수 있음.
- 강의가 2015년 말 기준으로 제작되었기 때문에 그 사이에 업데이트 된 코드들이 반영되어 있지 않아 구글링을 통해 해결해야 함. (예를 들어, sklearn.cross_validation이 이제는 제공되지 않고 sklearn.model_selection으로 통합)
- 코드를 자세히 다루지 않아 코딩 실력을 늘리려는 사람에게는 적합하지 않을 수 있음
개인적으로는 Andrew Ng의 Machine Learning 코스를 더 추천함. 유명한 강의 + 연습문제 + 수료증 지급 3가지 이유로 추천함!
1.3 파이썬 머신러닝 완벽 가이드(feat.inflearn)
학습 소요 시간
하루에 강의 약 3개씩 or 소단원 1개씩, 약 1달 반
학습 방법
인프런 파이썬 머신러닝 완벽 가이드 강의 + 책
개념은 책을 통해 학습, 소스코드 위주의 학습
학습 소감
CS109에서 배운 기본적인 개념 덕분에 이론적인 부분은 복습하는 개념으로 공부함
다만, CS109에서는 다양한 분류나 회귀 방법을 사용하지 않았고, 코드 설명도 부족했는데 이번 강의와 책은 기본적인 부분을 쉽고 자세하게 알려줌
- 장점
- 책에서 부족한 설명을 강의에서 보충해서 이해하기 쉬움
- 이론에 치중하기 보다는 캐글에서 유명한 데이터셋으로 직접 미니 프로젝트를 해볼 수 있게 하는 단원이 있어서 활용하는데 참고하기 좋음
- 단점
- 강의가 길고 책이 두꺼워서 머신러닝 처음 공부하는 사람들은 중간에 포기할 가능성 많음
- 코드 위주의 설명이기에 이론적인 부분을 공부하고 싶으면 다른 대학강의를 듣는 것이 더 좋아 보임
- 강의평에서도 볼 수 있듯이 어느 정도 머신러닝에 대한 개념이 있는 사람이 보는 것을 추천 처음 배우는 사람은 이걸 왜 쓰는지에 대한 감을 잡기 힘들 수 있음
Chapter2. 미니 프로젝트
이제 머신러닝에 대한 공부는 어느 정도 해봤으니 실제 대회에 참가해서 직접 데이터 전처리, 모델 학습, 하이퍼파라미터 튜닝 등을 해보자!
데이콘 베이직 Basic 심장 질환 예측 경진대회로 선정함
기본적인 EDA나 모델 성능을 향상 시킬 수 있는 코드들이 잘 공유되어 있고, 비교적 데이터셋이 학습하기에 적절하다고 생각했기 때문
1. 필요한 라이브러리 로드
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
2. 데이터셋 로드
- id: 데이터 고유 id
- age: 나이
- sex: 성별 (여자 = 0, 남자 = 1)
- cp: 가슴 통증(chest pain) 종류
- 0 : asymptomatic 무증상
- 1 : atypical angina 일반적이지 않은 협심증
- 2 : non-anginal pain 협심증이 아닌 통증
- 3 : typical angina 일반적인 협심증
- trestbps: (resting blood pressure) 휴식 중 혈압(mmHg)
- chol: (serum cholestoral) 혈중 콜레스테롤 (mg/dl)
- fbs: (fasting blood sugar) 공복 중 혈당 (120 mg/dl 이하일 시 = 0, 초과일 시 = 1)
- restecg: (resting electrocardiographic) 휴식 중 심전도 결과
- 0: showing probable or definite left ventricular hypertrophy by Estes' criteria
- 1: 정상
- 2: having ST-T wave abnormality (T wave inversions and/or ST elevation or depression of > 0.05 mV)
- thalach: (maximum heart rate achieved) 최대 심박수
- exang: (exercise induced angina) 활동으로 인한 협심증 여부 (없음 = 0, 있음 = 1)
- oldpeak: (ST depression induced by exercise relative to rest) 휴식 대비 운동으로 인한 ST 하강
- slope: (the slope of the peak exercise ST segment) 활동 ST 분절 피크의 기울기
- 0: downsloping 하강
- 2: flat 평탄
- 3: upsloping 상승
- ca: number of major vessels colored by flouroscopy 형광 투시로 확인된 주요 혈관 수 (0~3 개)
- Null값은 숫자 4로 인코딩됨
- thal: thalassemia 지중해빈혈 여부
- 0 = Null
- 1 = normal 정상
- 2 = fixed defect 고정 결함
- 3 = reversable defect 가역 결함
- target: 심장 질환 진단 여부
- 0: < 50% diameter narrowing
- 1: > 50% diameter narrowing
df = pd.read_csv('train.csv')
df.shape #(151,15)
EDA
df.describe()
히스토그램
plt.style.use('ggplot')
# 히스토그램
plt.figure(figsize=(25,20))
plt.suptitle('Data Histogram', fontsize=40)
# id는 제외하고 시각화
cols = df.columns[1:]
for i in range(len(cols)):
plt.subplot(5, 3, i+1)
plt.title(cols[i], fontsize=20)
if len(df[cols[i]].unique()) > 20:
plt.hist(df[cols[i]], bins=20, color='b', alpha=0.7)
else :
temp = df[cols[i]].value_counts()
plt.bar(temp.keys(), temp.values, width=0.5, alpha=0.7)
plt.xticks(temp.keys())
plt.tight_layout(rect=[0,0.03,1,0.95])
plt.show()
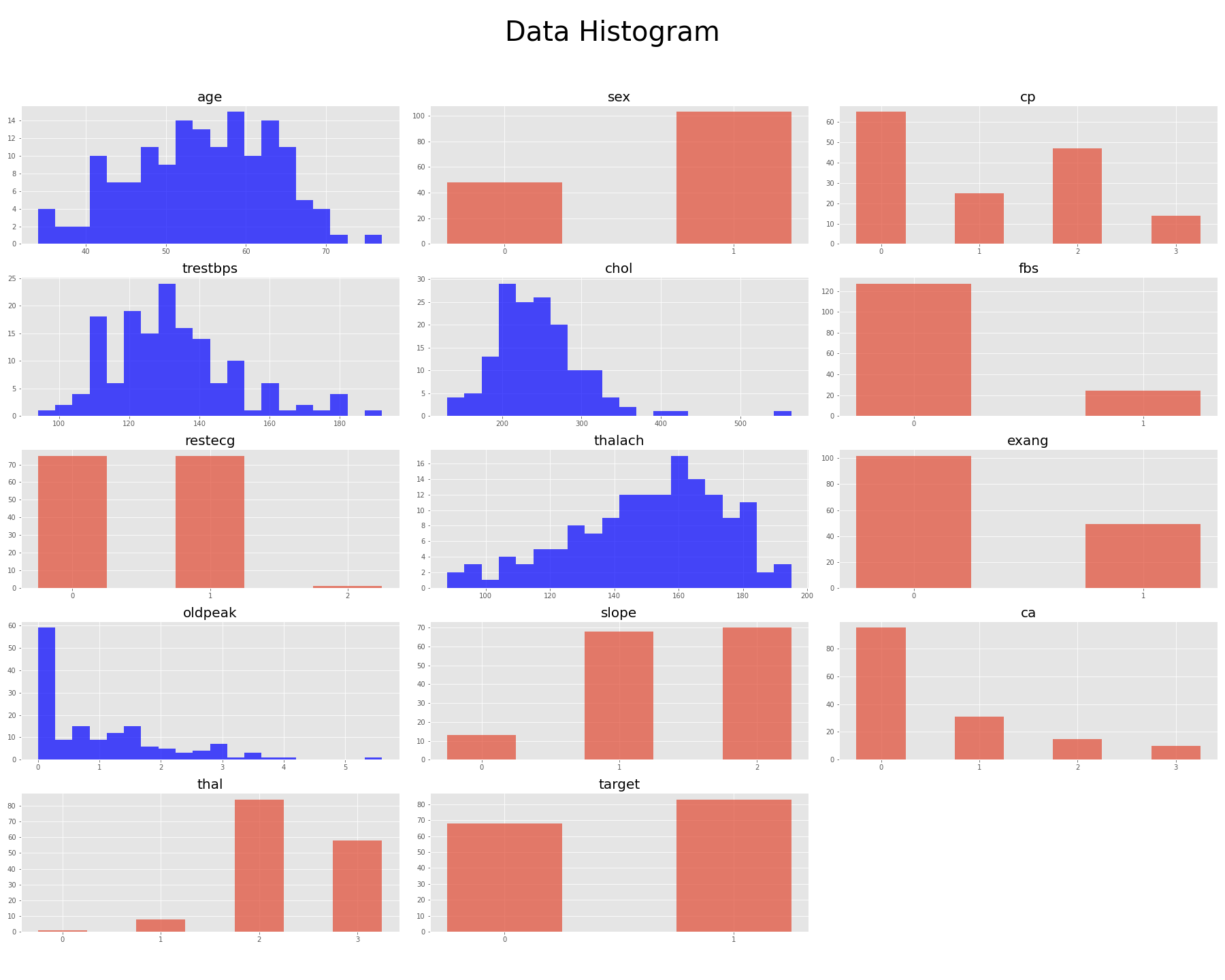
- 나이(age)는 정규 분포 형태를 이루는 것으로 보임
- 성별(sex)은 남자(1)가 여자(0)보다 약 2배임
- oldpeak이 왼쪽으로 치우침
- restecg와 thai의 경우 매우 적은 수의 극단값 클래스가 있음
- 심장 질환을 가진 사람이 조금 더 많음
Boxplots
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
# Boxplot 을 사용해서 데이터의 분포를 살펴보자.
plt.figure(figsize=(20,15))
plt.suptitle('Boxplots', fontsize=40)
# id 제외하고 시각화
cols = df.columns[1:-1]
for i in range(len(cols)):
plt.subplot(6,3,i+1)
plt.title(cols[i])
plt.boxplot(df[cols[i]])
plt.show()
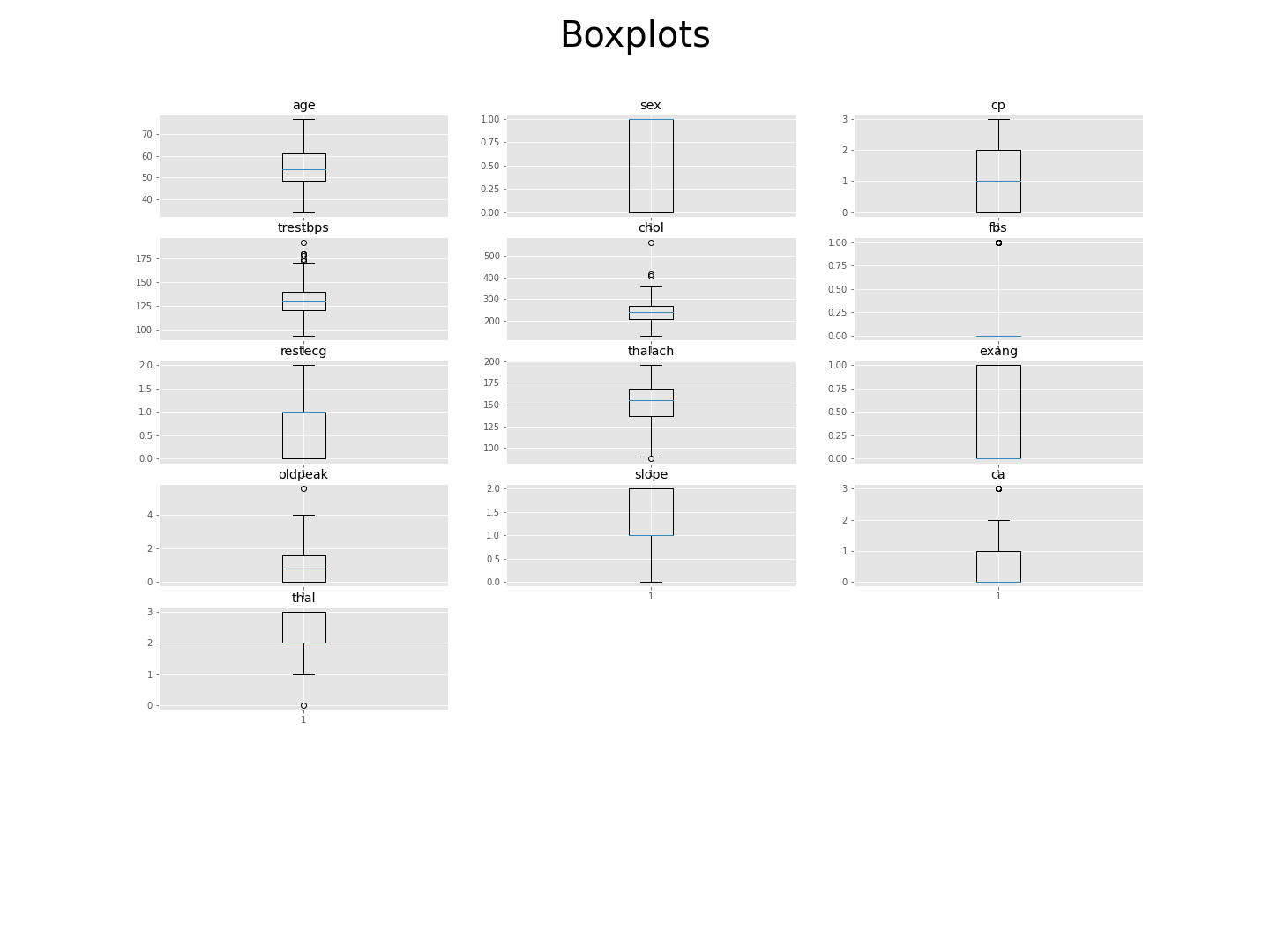
- threstbps, chol, fbs, oldpeak. ca, thal에서 이상치가 보임
상관관계
plt.figure(figsize=(20,10))
heat_table = df.drop(['id'], axis=1).corr()
heatmap_ax = sns.heatmap(heat_table, annot=True, cmap='coolwarm')
heatmap_ax.set_xticklabels(heatmap_ax.get_xticklabels(), fontsize=15, rotation=45)
heatmap_ax.set_yticklabels(heatmap_ax.get_yticklabels(), fontsize=15)
plt.title('correlation between features', fontsize=40)
plt.show()
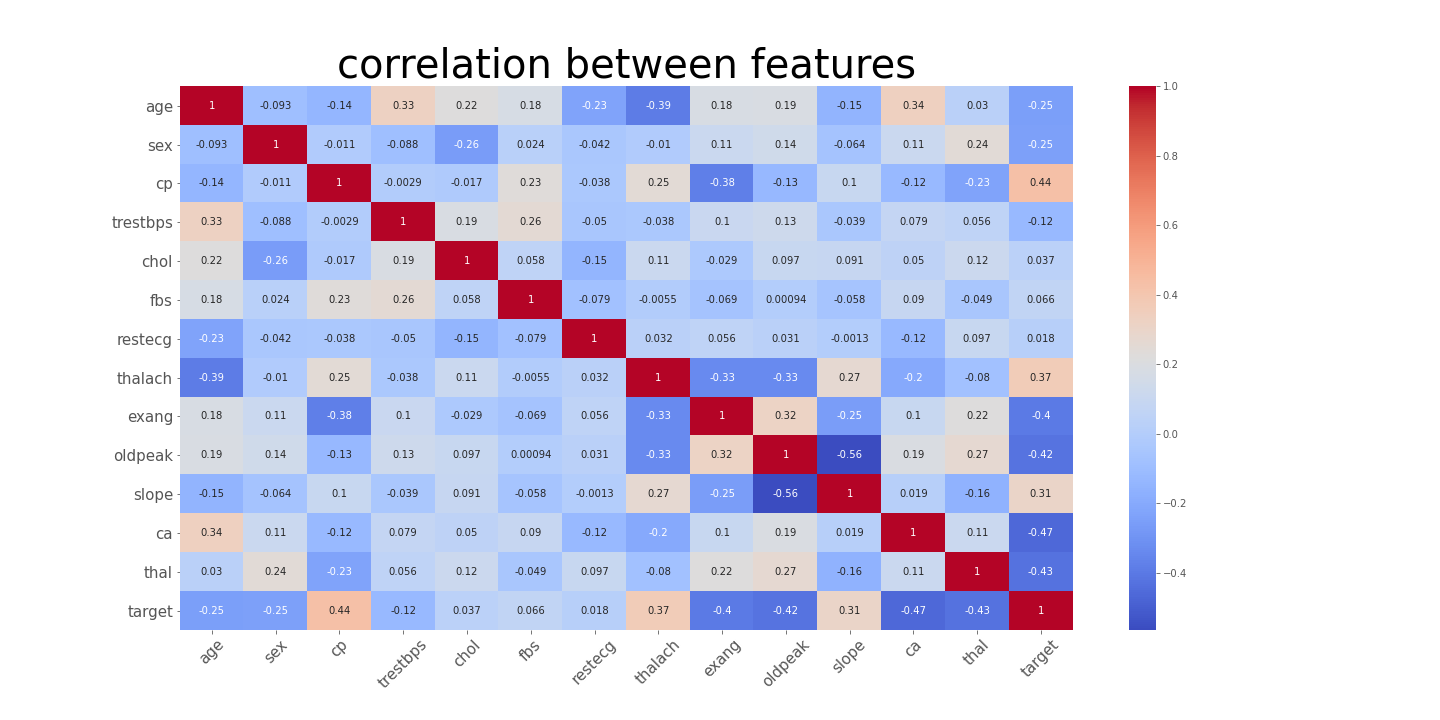
- target과 가장 강한 상관관계 -> ca로 -0.47정도의 상관관계
- ca(-0.47), cp(0.44), thal(-0.43), oldpeak(-0.42), exang(-0.4), thalach(0.37) 순으로 상관관계가 높음
target & feature와의 관계
age
sns.kdeplot(df.loc[df['target'] == 1, 'age'], color='red')
sns.kdeplot(df.loc[df['target'] == 0, 'age'], color = 'green')
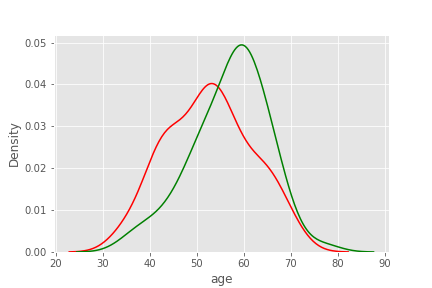
- 심장 질환에 걸린 사람들은 40-60이 주를 이룸
- 심장 질환이 걸리지 않은 사람들 중에서 60세 근방이 가장 많음
sex
plt.plot(figsize=(18,8))
sns.countplot('sex', hue='target', data=df)
plt.show()
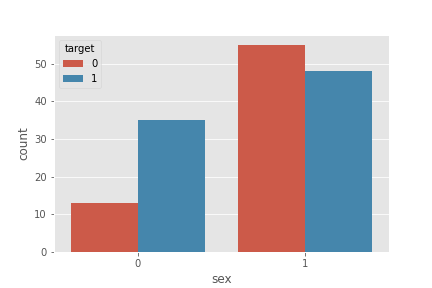
- 성별(sex)은 남자(1)가 여자(0)보다 약 2배임
- 여자는 질환이 있는 사람이 없는 사람보다 훨씬 많음
- 남자는 질환이 있는 사람의 수와 없는 사람의 수가 비슷함
cp
plt.plot(figsize=(18,8))
sns.countplot('cp', hue='target', data=df)
plt.show()
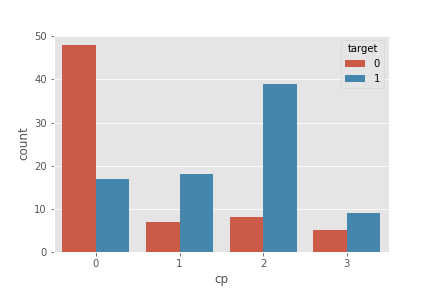
- 무증상이 가장 많음
- cp=2(non-anginal pain 협심증이 아닌 통증)일 때 심장질환일 확률이 높음
- cp=0(무증상)일 때 심장질환이 없을 확률이 높음
- cp=1(atypical angina 일반적이지 않은 협심증)이나 cp=3(typical angina 일반적인 협심증)일 때 심장질환이 있는 사람이 상대적으로 많음
trestbps
sns.kdeplot(df.loc[df['target'] == 1, 'trestbps'], color='red')
sns.kdeplot(df.loc[df['target'] == 0, 'trestbps'], color = 'green')
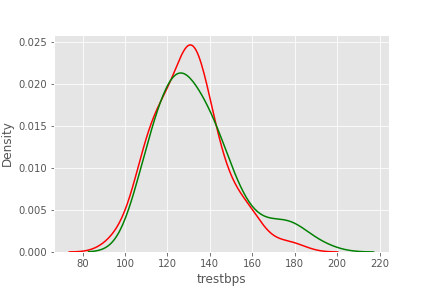
심장 질환 유무에 상관없이 비슷함
chol
sns.kdeplot(df.loc[df['target'] == 1, 'chol'], color='red')
sns.kdeplot(df.loc[df['target'] == 0, 'chol'], color = 'green')
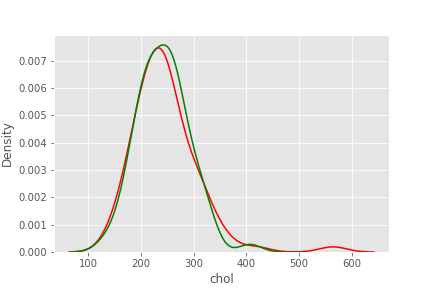
심장 질환 유무에 상관없이 비슷함
fbs
plt.plot(figsize=(18,8))
sns.countplot('fbs', hue='target', data=df)
plt.show()
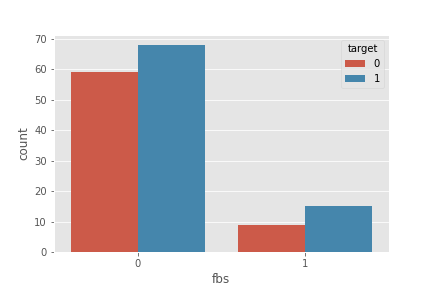
- 공복 중 혈당이 120mg/dl 이하가 초과보다 많음
- 심장질환과는 상관없이 공복 중 혈당 분포도가 비슷함
restecg
plt.plot(figsize=(18,8))
sns.countplot('restecg', hue='target', data=df)
plt.show()
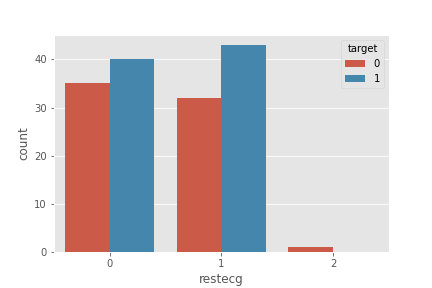
- restecg가 0이거나 1인 경우의 수가 많음
- restecg = 0(좌심실 비대가 보이는 경우)에 심장질환을 가질 가능성이 높음
- restecg = 1(정상)에 심장질환을 가질 가능성이 높음
- restecg = 2인 경우는 심장질환이 없음
thalach
sns.kdeplot(df.loc[df['target'] == 1, 'thalach'], color='red')
sns.kdeplot(df.loc[df['target'] == 0, 'thalach'], color = 'green')
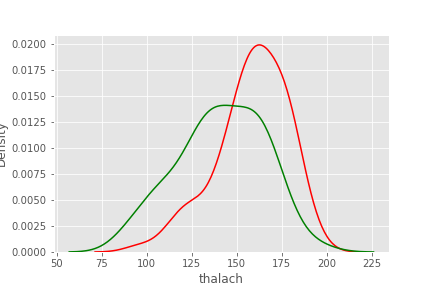
- 최대 심박수가 높을 수록 심장질환을 가질 가능성이 높음
exang
plt.plot(figsize=(18,8))
sns.countplot('exang', hue='target', data=df)
plt.show()
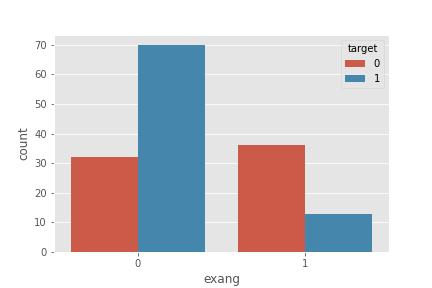
- exang=0(활동으로 인한 협심증 없음)일 때 심장질환 발생 가능성이 높음
- exang=1(활동으로 인한 협심증 있음)일 때 심장질환 발생 가능성이 적음
oldpeak
sns.kdeplot(df.loc[df['target'] == 1, 'oldpeak'], color='red')
sns.kdeplot(df.loc[df['target'] == 0, 'oldpeak'], color = 'green')
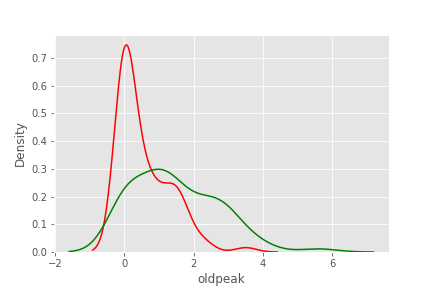
- oldpeak(휴식 대비 운동으로 인한 ST 하강)이 적을수록 심장질환 확률이 높음
slope
plt.plot(figsize=(18,8))
sns.countplot('slope', hue='target', data=df)
plt.show()
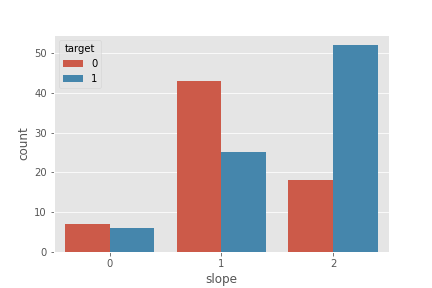
- slope=2(상승)일 때 심장질환 확률이 높음
- slope=0(하강)/1(평탄)일 때는 심장질환 확률이 낮음
ca
plt.plot(figsize=(18,8))
sns.countplot('ca', hue='target', data=df)
plt.show()
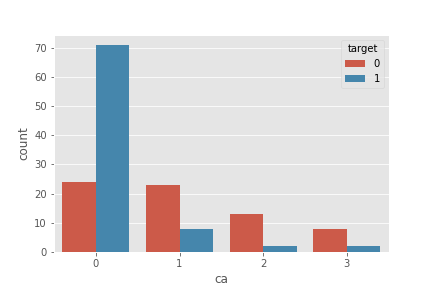
- ca=0(형광 투시로 확인된 주요 혈관 수)일 때 심장질환 확률이 높음
thal
plt.plot(figsize=(18,8))
sns.countplot('thal', hue='target', data=df)
plt.show()
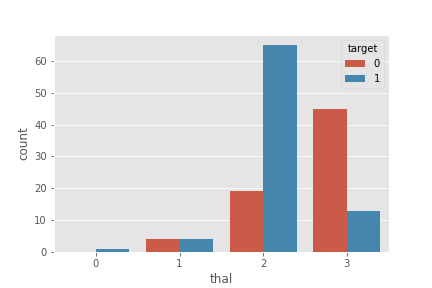
- **thal=2(고정결함)일 때 심장질환 확률이 높음
- thal=3(가역결함)일 때는 심장질환 확률이 낮음
3. Feature Engineering
3.1 결측치 다루기
df.isnull().sum() # 모두 0임
thal
df['thal_nan'] = df['thal'].replace(0,np.nan)
df['ca_nan'] = df['ca'].replace(4,np.nan)
df['thal_nan'].isnull().sum() # 1
df['ca_nan'].isnull().sum() # 0
# 결측치 비율 -> 매우 작으므로 drop
df['thal_nan'].isnull().mean() # 0.006622516556291391
index1 = df[df['thal'] == 0].index
print(index1) # Int64Index([129], dtype='int64')
df.drop(index1, inplace=True)
3.2 정규분포 만들기
trestbps
sns.distplot(df['trestbps'])
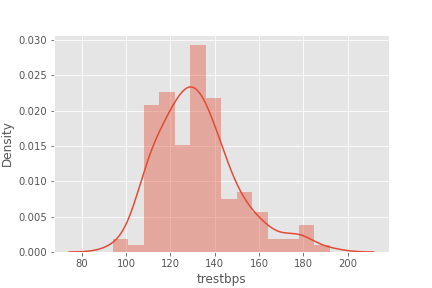
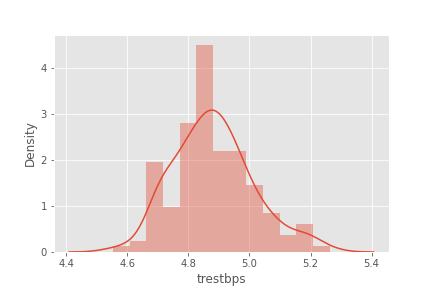
sns.distplot(np.log1p(df['trestbps']))
chol
sns.distplot(df['chol'])
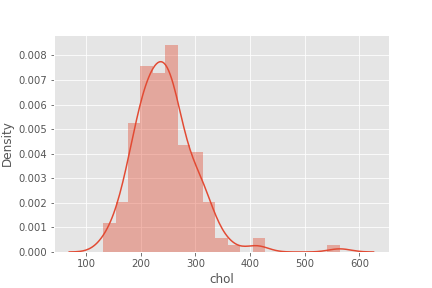
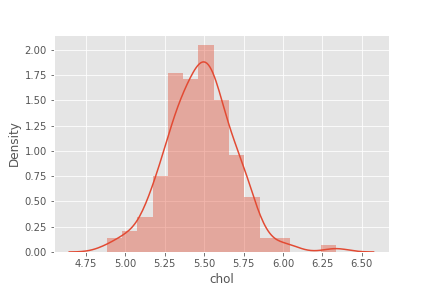
sns.distplot(np.log1p(df['chol']))
df['trestbps'] = np.log1p(df['trestbps'])
df['chol'] = np.log1p(df['chol'])
3.3 이상치 다루기
oldpeak
plt.figure(figsize=(15,2))
sns.boxplot(df['oldpeak'])

trestbps
plt.figure(figsize=(15,2))
sns.boxplot(df['trestbps'])

chol
plt.figure(figsize=(15,2))
sns.boxplot(df['chol'])

thalach
plt.figure(figsize=(15,2))
sns.boxplot(df['thalach'])

features = ['oldpeak','trestbps','chol','thalach']
for feature in features:
print(feature)
IQR3 = df[feature].quantile(0.75)
IQR1 = df[feature].quantile(0.25)
IQR = IQR3 - IQR1
OUT_down= IQR1 - (1.5*IQR)
OUT_up = IQR3 + (1.5*IQR)
index1 = df[df[feature] > OUT_up].index
print(index1)
index2 = df[df[feature] < OUT_down].index
print(index2)
df.drop(index1, inplace=True)
df.drop(index2, inplace=True)
3.4 Scaling
from sklearn.preprocessing import StandardScaler
transform_data = df.drop(columns=['id', 'age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg', 'exang', 'oldpeak', 'slope', 'ca','thal', 'target'])
scaler = StandardScaler()
std_transfrom_data = scaler.fit_transform(transform_data)
df[transform_data.columns] = std_transfrom_data
4. 모델 학습
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import f1_score
from sklearn.metrics import plot_confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix, roc_auc_score
Logistic Regression
X = df.iloc[:, 1:-1] # id,target 제거
y = df.iloc[:,-1] # target만 선택
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
lr_clf = LogisticRegression(random_state=156)
lr_clf.fit(X_train,y_train)
pred = lr_clf.predict(X_test)
print('Accuacy Score: ', accuracy_score(y_test, pred)) # 0.9285714285714286
print('ROC AUC Score: ', roc_auc_score(y_test, pred)) # 0.9166666666666667
print(f'f1_score : {f1_score(y_test, pred)}') # 0.9411764705882353
from sklearn.model_selection import GridSearchCV
params = {'penalty' : ['l2', 'l1'],
'C' : [0.01, 0.1, 1, 5, 10]}
lr_grid_clf = GridSearchCV(lr_clf, param_grid=params, scoring='accuracy', cv=5)
lr_grid_clf.fit(X_train, y_train)
print('최적 하이퍼 파라미터:{0}, 최적 평균 정확도: 1:.3f}'.format(lr_grid_clf.best_params_, lr_grid_clf.best_score_))
# 최적 하이퍼 파라미터:{'C': 5, 'penalty': 'l2'}, 최적 평균 정확도:0.821
pred = lr_grid_clf.predict(X_test)
print('Accuacy Score: ', lr_grid_clf.best_score_) # 0.8209486166007907
print('ROC AUC Score: ', roc_auc_score(y_test, pred)) # 0.9166666666666667
print(f'f1_score : {f1_score(y_test, pred)}') # 0.9411764705882353
DecisionTree
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=5, random_state=42)
dt_clf = DecisionTreeClassifier(random_state=42)
param_grid = {'max_depth' : range(3,12),
'max_features' : [0.3, 0.5, 0.7, 0.9, 1]}
grid_dt_clf = GridSearchCV(dt_clf, param_grid=param_grid, n_jobs=-1, cv=5, verbose=2)
grid_dt_clf.fit(X_train, y_train)
print(grid_dt_clf.best_params_) # {'max_depth': 6, 'max_features': 0.7}
print(grid_dt_clf.best_score_) # 0.8109890109890111
pred = grid_dt_clf.predict(X_test)
print('Accuacy Score: ', grid_dt_clf.best_score_) # 0.8109890109890111
print('ROC AUC Score: ', roc_auc_score(y_test, pred)) # 0.8125
print(f'f1_score : {f1_score(y_test, pred)}') # 0.8484848484848485
여러 개의 알고리즘 사용해서 비교하기
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
estimators = [DecisionTreeClassifier(random_state=42),
RandomForestClassifier(random_state=42),
GradientBoostingClassifier(random_state=42),
XGBClassifier(random_state=42),
LGBMClassifier(random_state=42)]
estimators
results = []
for estimator in estimators:
result = []
result.append(estimator.__class__.__name__)
results.append(result)
results
from sklearn.model_selection import RandomizedSearchCV
max_depth = np.random.randint(2,20,10)
param_distributions = {'max_depth':max_depth}
results = []
for estimator in estimators:
result = []
if estimator.__class__.__name__ != 'DecisionTreeClassifier':
param_distributions['n_estimators'] = np.random.randint(100,200,10)
clf = RandomizedSearchCV(estimator,
param_distributions,
n_iter=100,
scoring='accuracy',
n_jobs=-1,
cv=5,
verbose=2)
clf.fit(X_train, y_train)
result.append(estimator.__class__.__name__)
result.append(clf.best_params_)
result.append(clf.best_score_)
result.append(clf.score(X_test, y_test))
result.append(clf.cv_results_)
results.append(result)
df = pd.DataFrame(results,columns=['estimator','best_params','train_score','test_score','cv_result'])

5. 결과 제출
test_set = pd.read_csv('test.csv')
test_set.head()
test_set['trestbps'] = np.log1p(test_set['trestbps'])
test_set['chol'] = np.log1p(test_set['chol'])
transform_data = test_set.drop(columns=['id', 'age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg', 'exang', 'oldpeak', 'slope', 'ca','thal'])
scaler = StandardScaler()
std_transfrom_data = scaler.fit_transform(transform_data)
test_set[transform_data.columns] = std_transfrom_data
test_X = test_set.iloc[:,1:] # id 제외 후 모든 데이터 사용
# 가장 f1 score값이 높았던 lr_grid_clf 사용
best_estimator = lr_grid_clf.best_estimator_
preds = best_estimator.predict(test_X)
submission = pd.read_csv('sample_submission.csv')
submission['target'] = preds
submission.to_csv('final.csv', index=False)
6. 느낀 점
-
아무리 좋은 강의와 책을 독학하더라도 실제로 대회에 나가서 데이터를 가지고 머신러닝을 돌려보지 않으면 절대 실력이 늘지 않음
-
머신러닝 기법과 하이퍼파라미터 튜닝도 중요하지만 feture engineering이 훨씬 성능 향상에 크게 기여함을 알게 됨
-
이번 프로젝트는 단순히 로지스틱 회귀, Tree기반, xgb, lgbm 등을 사용했지만 다음 번에는 앙상블에 도전해 볼 계획임
-
비록 f1 score를 90점 대로 높이지 못했지만 앞으로 계속해서 공모전에 참가할 예정