지역별 건강 행동 격차 원인 분석
by 나다경
1. 서론
1.1 건강 행동
건강행동이란 건강증진이나 질병 예방을 위해 어떤 행동을 하거나 하지 않는 것을 말하며, 음주, 흡연, 식습관, 주관적 건강인지 등이 이와 관련이 있다.
“흡연,음주 감소했지만 지역 간 격차 해소 노력 필요“, 대한민국 정책브피핑
“최근 4년간 국민건강지표 악화… 지역별 격차는 여전“, 청년의사
“지난해 흠연 음주 줄었지만 활동량 줄어들어 지역간 건강관리 커", 매일경제
최근의 기사를 통해 건강행동의 동향을 살펴보면, 건강행동 지표 자체는 좋아지고 있으나 지역 간 격차는 여전히 큰 상황이다. 사실 개인의 식습관이나, 흡연 여부 등은 개인의 특성이나 선택에서 비롯된 것으로 생각하기 쉽다. 하지만 건강행동은 사회와 환경에도 영향을 받아 형성되며 이것이 결과적으로 집단건강을 만든다고 할 수 있다.
이런 맥락에서 건강행동의 지역 격차를 만드는 사회적인 요인이 무엇인지에 대해 의문을 품고 프로젝트를 시작하게 되었다.
2. 분석과정
2.1 활용 데이터 및 변수
변이 요인을 찾기 위해서는 분석에 사용될 변수를 선정하는 작업이 필요했는데, 선행연구 탐색을 통해 선정했다.
김동현, 2010, "2008년 지역사회건강조사를 이용한 지역 간 건강행태 변이요인에 대한 분석연구"
김동현의 이 보고서는 2008년 지역사회건강조사를 기초로 하여 흡연, 음주를 비롯한 여러 건강행태의 지역 간 변이 요인을 규명한 보고서다. 건강 행동의 요인과 지역 격차를 주제로 한다는 점에서 분석 방향이 같고, 또 약 10년 전의 데이터를 사용했기 때문에 다시 분석해볼 필요성이 크다고 판단하여 이 분석의 참고자료로 삼았다.
분석에 사용된 변수와 데이터는 다음과 같다.
(1) 건강행동 데이터
- 흡연율
- 고위험 음주율
(2) 도시환경 데이터
- 천명당 담배 소매업체수
- 천명당 주점수
- 1인당 공원 면적
-
출처 : KOSIS 공원(2019)
(3) 사회경제적 환경 데이터
- 1인당 보험료
-
출처 : KOSIS 시군구(서울,인천,경기,강원)별 보험료 현황(2019)
KOSIS 시군구(대전,세종,충북,충남)별 보험료 현황(2019)
- 이혼율
- 재정자립도
(4) 인구 데이터
2.2 분석 방향

분석과정은 그림과 같다. 앞서 제시했듯이 건강행동, 도시환경, 사회경제적 환경 세 파트에서 데이터를 수집했다. 이를 통해 전국 252개 시군구를 대상으로, 시점은 2019년으로 지정하여 분석을 시행했고, 결과적으로 가장 유의한 결정요인과 지역적 특성을 도출했다. 나아가 건강행동 격차를 축소하고 집단 수준에서의 건강을 증진할 수 있는 방안도 고민해보았다.
3. 분석 결과
분석 결과 파트에서는 건강행동의 지역 격차 현황을 제시하고, 그 결정요인을 도시환경 측면과 사회경제적 환경 측면으로 나누어 규명하려 했다.
각 데이터의 전처리 과정은 다음과 같다.
3.1 전처리 과정
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
import platform
from matplotlib import font_manager, rc
path = "c:/Windows/Fonts/malgun.ttf"
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Unknown system... sorry~~~~')
# 흡연율 전처리
smoking = pd.read_excel('흡연율.xlsx', header = 1)
smoking.fillna(method='pad', inplace = True)
smoking.rename(columns = {'시군구별(1)' : '광역시도',
'시군구별(2)' : '시도',
'시군구별(3)' : '시군구'}, inplace = True)
#지역 이름 바꿔주기
smoking1 = smoking[(smoking['시군구'] != '소계')]
smoking1['지역'] = smoking['시도'] + ' ' + smoking['시군구']
smoking['시군구'] = smoking1['지역']
smoking['시군구'].fillna(smoking['시도'], inplace = True)
smoking = smoking.drop(['시도'], axis=1)
#다운로드
#smoking.to_csv('smoking.csv', encoding='cp949')
# 고위험 음주율 전처리
danger_drink = pd.read_excel('고위험음주율.xlsx', header = 1)
danger_drink.fillna(method='pad', inplace = True)
danger_drink.rename(columns = {'시군구별(1)' : '광역시도',
'시군구별(2)' : '시도',
'시군구별(3)' : '시군구'}, inplace = True)
#지역 이름 바꿔주기
danger_drink1 = danger_drink[(danger_drink['시군구'] != '소계')]
danger_drink1['지역'] = danger_drink['시도'] + ' ' + danger_drink['시군구']
danger_drink['시군구'] = danger_drink1['지역']
danger_drink['시군구'].fillna(danger_drink['시도'], inplace = True)
danger_drink = danger_drink.drop(['시도'], axis=1)
#다운로드
#danger_drink.to_csv('danger_drink.csv', encoding='cp949')
#단란주점 전처리
danlan = pd.read_csv('./fulldata_07_23_01_P_단란주점영업.csv', encoding='CP949')
danlan = danlan.drop(['번호', '개방서비스명', '개방서비스id', '개방자치단체코드', '관리번호', '영업상태구분코드', '상세영업상태코드',
'상세영업상태명', '휴업시작일자', '휴업종료일자', '재개업일자', '소재지전화', '소재지면적',
'소재지우편번호', '도로명우편번호', '데이터갱신구분', '업태구분명',
'위생업태명', '남성종사자수', '여성종사자수', '영업장주변구분명', '등급구분명', '급수시설구분명',
'총종업원수', '본사종업원수', '공장사무직종업원수', '공장판매직종업원수', '공장생산직종업원수', '건물소유구분명',
'보증액', '월세액', '다중이용업소여부', '시설총규모', '전통업소지정번호', '전통업소주된음식', '홈페이지', 'Unnamed: 47',
'최종수정시점', '데이터갱신일자', '인허가취소일자'], axis=1)
#2019년 영업 업체만 뽑아내기_폐업
con1 = danlan['영업상태명'] == '폐업'
con2 = danlan['인허가일자'] <= 20191231
con3 = danlan['폐업일자'] <= 20191231
con4 = danlan['폐업일자'] < 20190101
danlan_closed = danlan[con1 & con2& con3 & ~con4]
#danlan_closed.to_excel('단란주점_폐업.xlsx')
#2019년 영업 업체만 뽑아내기_영업
con1 = danlan['영업상태명'] == '영업/정상'
con2 = danlan['인허가일자'] <= 20191231
danlan_open = danlan[con1 & con2]
#danlan_open.to_excel('단란주점_영업.xlsx')
#폐업, 영업 병합
danlan2 = pd.concat([danlan_closed, danlan_open], axis=0)
danlan2 = danlan2.reset_index()
#다운로드
#danlan2.to_excel('단란주점_현황.xlsx')
#유흥주점 전처리
heung = pd.read_csv('fulldata_07_23_02_P_유흥주점영업.csv', encoding = 'cp949')
heung = heung.drop(['번호', '개방서비스명', '개방서비스id', '개방자치단체코드', '관리번호', '영업상태구분코드', '상세영업상태코드',
'상세영업상태명', '휴업시작일자', '휴업종료일자', '재개업일자', '소재지전화', '소재지면적',
'소재지우편번호', '도로명우편번호', '데이터갱신구분', '업태구분명',
'위생업태명', '남성종사자수', '여성종사자수', '영업장주변구분명', '등급구분명', '급수시설구분명',
'총종업원수', '본사종업원수', '공장사무직종업원수', '공장판매직종업원수', '공장생산직종업원수', '건물소유구분명',
'보증액', '월세액', '다중이용업소여부', '시설총규모', '전통업소지정번호', '전통업소주된음식', '홈페이지', 'Unnamed: 47',
'최종수정시점', '데이터갱신일자', '인허가취소일자'], axis=1)
#2019년 영업 업체만 뽑아내기_폐업
con1 = heung['영업상태명'] == '폐업'
con2 = heung['인허가일자'] <= 20191231
con3 = heung['폐업일자'] <= 20191231
con4 = heung['폐업일자'] < 20190101
heung_closed = heung[con1 & con2& con3 & ~con4]
#heung_closed.to_excel('유흥주점_폐업.xlsx')
#2019년 영업 업체만 뽑아내기_영업
con1 = heung['영업상태명'] == '영업/정상'
con2 = heung['인허가일자'] <= 20191231
heung_open = heung[con1 & con2]
#heung_open.to_excel('유흥주점_영업.xlsx')
#폐업, 영업 병합
heung2 = pd.concat([heung_closed, heung_open], axis=0)
heung2 = heung2.reset_index()
#heung2.to_excel('유흥주점_현황.xlsx') #다운로드
#공원 전처리
park = pd.read_excel('공원_20210818171150.xlsx')
park = park.drop(['시점'], axis=1)
park = park.drop(park.index[:2])
park = park.rename({'소재지(시군구)별(1)' : '광역시도', '소재지(시군구)별(2)' : '시도', '계' : '시설수(개소)', 'Unnamed: 4' : '면적'}, axis=1)
park.fillna(method='pad', inplace=True)
#필요한 데이터만 남기기
park_sum = park[park['시도'] == '소계'].index
park = park.drop(park_sum)
#보험료 전처리
bohum = pd.read_excel('시군구_전국_보험료 현황.xlsx')
bohum = bohum.drop(['시점'], axis=1)
bohum = bohum.rename({'시군구별(1)' : '광역시도', '시군구별(2)' : '시도', '계' : '보험료'}, axis=1)
#필요한 데이터만 남기기
bohum.fillna(method='pad', inplace=True)
bohum_sum = bohum[bohum['시도'] == '소계'].index
bohum = bohum.drop(bohum_sum)
bohum = bohum.set_index('시도')
#1인당 보험료 구하기_인구 데이터 불러오기
pop = pd.read_excel('행정구역_시군구_별__성별_인구수_20210819123743.xlsx')
pop = pop.drop(['시점'], axis=1)
pop = pop.rename({'행정구역(시군구)별' : '시도', '총인구수 (명)' : '인구수'}, axis=1)
pop = pop.set_index('시도')
#데이터 병합
#bohum_pop_merge.xlsx 는'bohum'과 'pop'을 엑셀에서 병합한 파일.
bohum_merge = pd.read_excel('bohum_pop_merge.xlsx')
bohum_merge['1인당 보험료'] = bohum_merge['보험료'] / bohum_merge['인구수']
bohum_merge = bohum_merge.round(2)
bohum_merge = bohum_merge.set_index(['광역시도', '시도'])
#bohum_merge.to_excel('bohum_merge.xlsx') #다운로드
#흡연/음주, 담배소매업, 주점, 공원 병합한 데이터
environment = pd.read_excel('environment.xlsx')
environment = environment.set_index(['시도'])
environment = environment.drop(['Unnamed: 7','Unnamed: 8','Unnamed: 9','Unnamed: 10','Unnamed: 11','Unnamed: 12','Unnamed: 13',
'Unnamed: 14','Unnamed: 15','Unnamed: 16','Unnamed: 17','Unnamed: 18','Unnamed: 19','Unnamed: 20',
'Unnamed: 21','Unnamed: 22','Unnamed: 23','Unnamed: 24','Unnamed: 25'], axis=1)
#광역시도별로 병합한 데이터
merge = pd.read_excel('smoking_drink_merge_broad.xlsx')
merge = merge.set_index(['광역시도'])
#흡연/음주, 보험료, 조이혼율, 재정자립도 병합한 데이터
#이 세 변수의 경우 엑셀에서 한번 더 전처리 과정을 거쳐 건강행동 데이터도 병합된 '사회통합.xlsx'파일을 사용했다
social = pd.read_excel('사회 통합.xlsx')
#광역시도별로 병합한 데이터
merge2 = pd.read_excel('social_merge_final.xlsx')
merge2 = merge2.set_index(['광역시도'])
3.2 건강 행동 지역 격차 현황 분석
!pip install googlemaps
!pip install folium
import json
import folium
import googlemaps
import warnings
warnings.simplefilter(action = 'ignore', category = FutureWarning)
geo_path = '05. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding = 'utf-8'))
3.2.1 흡연율과 고위험 음주율 현황 분석
건강행동 지표는 흡연율과 고위험 음주율로 설정했다.
#흡연율 지역별 분포
bins = list(environment['흡연율'].quantile([0, 0.25, 0.5, 0.75, 1]))
map = folium.Map(location = [36, 127], zoom_start=7)
folium.Choropleth(geo_data = geo_str,
data = environment,
columns = [environment.index, '흡연율'],
fill_color='PuRd',
key_on = 'feature.id',
legend_name = '흡연율',
bins=bins,
reset=True).add_to(map)
map
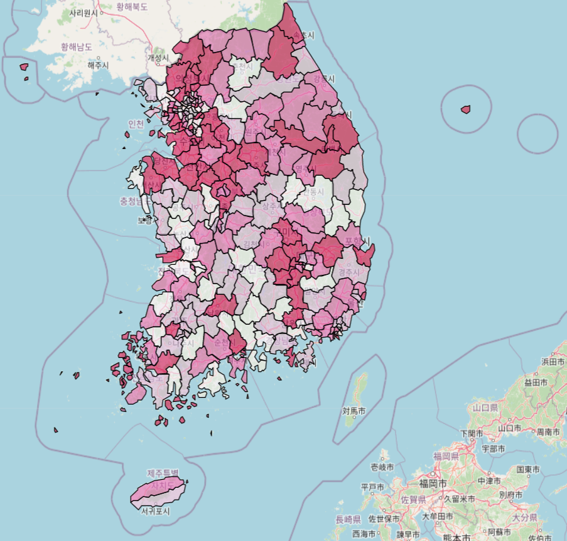
지도에 나타난 경향성을 보면, 현재 흡연율은 경기, 충청, 경상 일부 지역이 높지만 세종, 서울과 전라권은 비교적 낮은 걸 알 수 있다.
#고위험 음주율 지역별 분포
bins = list(environment['고위험 음주율'].quantile([0, 0.25, 0.5, 0.75, 1]))
map = folium.Map(location = [36, 127], zoom_start=7)
folium.Choropleth(geo_data = geo_str,
data = environment,
columns = [environment.index, '고위험 음주율'],
fill_color='PuRd',
key_on = 'feature.id',
legend_name = '고위험 음주율',
bins=bins,
reset=True).add_to(map)
map
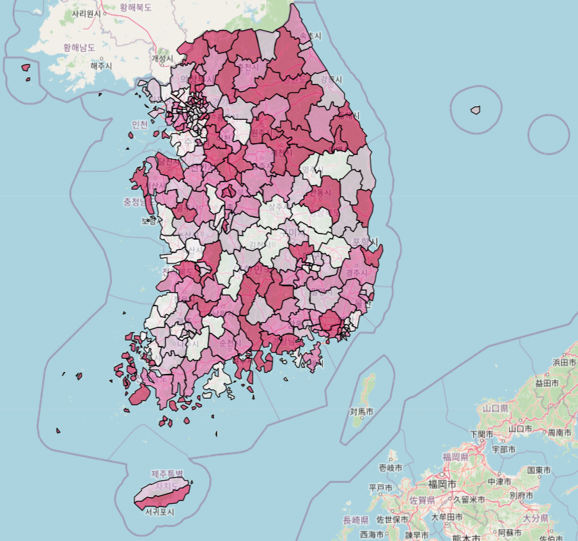
- 고위험 음주율: 최근 1년 동안 음주한 사람 중에서 남자는 한 번의 술자리에서 7잔 이상, 여자는 5잔 이상을 주 2회 이상 마시는 사람의 분율. (해당 연도 및 지역의 인구 구성비를 그대로 반영하여 산출된 ‘조율’을 사용)
고위험 음주율은 강원, 충청, 경남 지역이 높고, 세종, 경북, 전라권은 낮은 편이다.
종합해보면, 흡연율과 음주율에 지역 격차가 존재하고, 특히 충청, 경상, 전라 지역에서는 일관된 결과가 나타나는 것을 알 수 있다.
3.2.2 흡연율이 높은 지역에서 고위험 음주율도 높을까?
이 질문을 해결하기 위해 상관분석을 실시했다.
corr = environment.corr(method='pearson')
smoking_corr = corr.drop(['천명당 담배 소매업수', '천명당 주점수', '1인당 공원 면적'], axis=1)
smoking_corr = smoking_corr.drop(['천명당 담배 소매업수', '천명당 주점수', '1인당 공원 면적'])
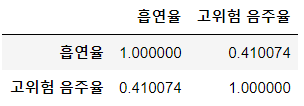
smoking_corr
smoking_heatmap = sns.heatmap(smoking_corr, cbar = True, annot = True, annot_kws={'size' : 18}, fmt = '.2f', square = True, cmap = 'Blues')
smoking_heatmap
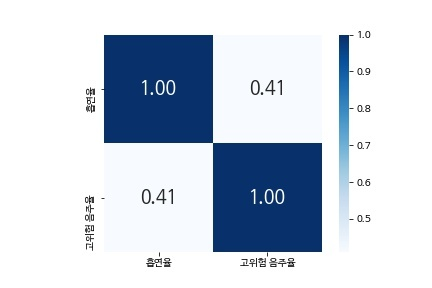
이 두 건강행동, 흡연율과 고위험 음주율의 상관계수는 0.41로 양의 상관관계를 가진다.
즉 흡연율이 높은 지역에서 고위험 음주율도 높은 경향을 보이기에, 음주와 흡연, 즉 건강행동을 유발하는 집단적인 수준의 요인이 있을 것이라 가정할 수 있다.
그래서 그 요인들을 밝혀내기 위해 상관분석을 실시했다. 유의한 변수를 찾아내는 과정을 보여주기 위해 먼저 각 변수 간 상관성을 밝히고, 상관계수가 0.2, 즉 약한 상관관계 이상인 변수들을 골라내 해당 변수의 영향을 크게 받는 지역을 골라보았다.
3.3 도시환경 측면의 요인 분석
3.3.1 지도 시각화로 분포 알아보기
먼저 도시환경 측면의 요인을 찾아보겠다. 선정된 변수는 1인당 담배소매업체 수, 1인당 주점 수, 1인당 공원 면적이다.
#천명당 담배소매업체 수 지역별 분포
bins = list(environment['천명당 담배 소매업수'].quantile([0, 0.25, 0.5, 0.75, 1]))
map = folium.Map(location = [36, 127], zoom_start=7)
folium.Choropleth(geo_data = geo_str,
data = environment,
columns = [environment.index, '천명당 담배 소매업수'],
fill_color='PuRd',
key_on = 'feature.id',
legend_name = '천명당 담배 소매업수',
bins=bins,
reset=True).add_to(map)
map

- 천 명당 담배 소매업체 수 : 담배를 매입하여 일반인에게 판매하는 업체. 편의점도 포함된다.
지역 분포를 보면 세종, 서울, 전라권을 제외한 대부분 지역이 높게 나온다.
#천명당 주점 수 지역별 분포
bins = list(environment['천명당 주점수'].quantile([0, 0.25, 0.5, 0.75, 1]))
map = folium.Map(location = [36, 127], zoom_start=7)
folium.Choropleth(geo_data = geo_str,
data = environment,
columns = [environment.index, '천명당 주점수'],
fill_color='PuRd',
key_on = 'feature.id',
legend_name = '천명당 주점수',
bins=bins,
reset=True).add_to(map)
map
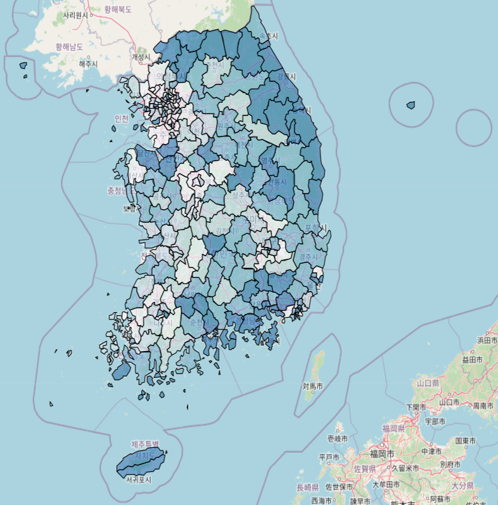
- 주점 : 단란주점과 유흥주점 수의 합으로 정의했다.
강원, 부산과 경남 지역에 많고, 서울과 전라 지역에서 적다.
#1인당 공원면적 지역별 분포
bins = list(environment['1인당 공원 면적'].quantile([0, 0.25, 0.5, 0.75, 1]))
map = folium.Map(location = [36, 127], zoom_start=7)
folium.Choropleth(geo_data = geo_str,
data = environment,
columns = [environment.index, '1인당 공원 면적'],
fill_color='PuRd',
key_on = 'feature.id',
legend_name = '1인당 공원 면적',
bins=bins,
reset=True).add_to(map)
map
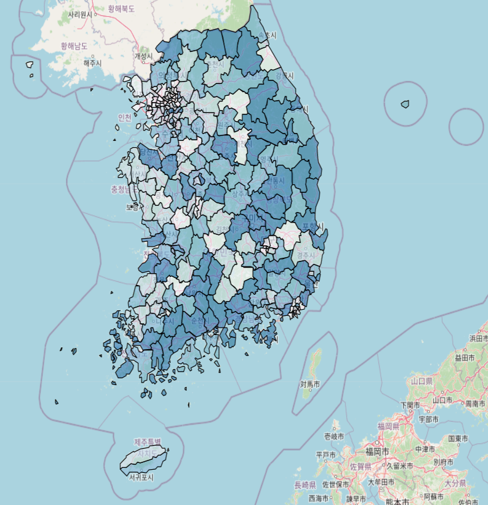
1인당 공원 면적은 서울, 경기, 인천 지역이 다른 지역보다 공원 면적이 조금 좁은 것을 알 수 있다.
3.3.2 건강행동과 도시환경 간의 관계
분석 전 세운 가설은, '천 명당 담배소매업체 수와 주점 수가 많을수록 흡연, 음주율이 높고, 1인당 공원 면적이 넓을수록 낮다'였다.
smoking_corr = corr.drop(['1인당 공원 면적', '고위험 음주율'], axis=1)
smoking_corr = smoking_corr.drop(['1인당 공원 면적', '고위험 음주율'])
smoking_corr

#흡연율과 도시환경의 관계
smoking_heatmap = sns.heatmap(smoking_corr, cbar = True, annot = True, annot_kws={'size' : 18}, fmt = '.2f', square = True, cmap = 'Blues')
smoking_heatmap
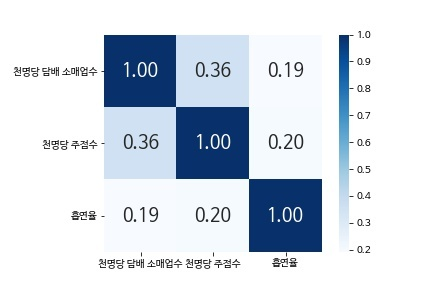
흡연율과 천 명당 담배소매업체 수는 매우 약한 양의 상관관계를, 흡연율과 천 명당 주점 수는 0.2로 약한 양의 상관관계를 보인다.
#흡연율과 천명당 주점 수
fp1 = np.polyfit(merge['천명당 주점수'], merge['흡연율'],1)
f1 = np.poly1d(fp1)
fx = np.linspace(45, 0, 17)
plt.figure(figsize=(8,8))
plt.scatter(merge['천명당 주점수'], merge['흡연율'], s=50)
plt.plot(fx, f1(fx), ls='dashed', lw=3, color='g')
# 텍스트 만들어주기(점 오른쪽에 위치하도록)
for n in range(17):
plt.text(merge['천명당 주점수'][n]*1.04, merge['흡연율'][n]*0.995,
merge.index[n], fontsize=15)
plt.xlabel('천명당 주점수')
plt.ylabel('흡연율')
plt.show()
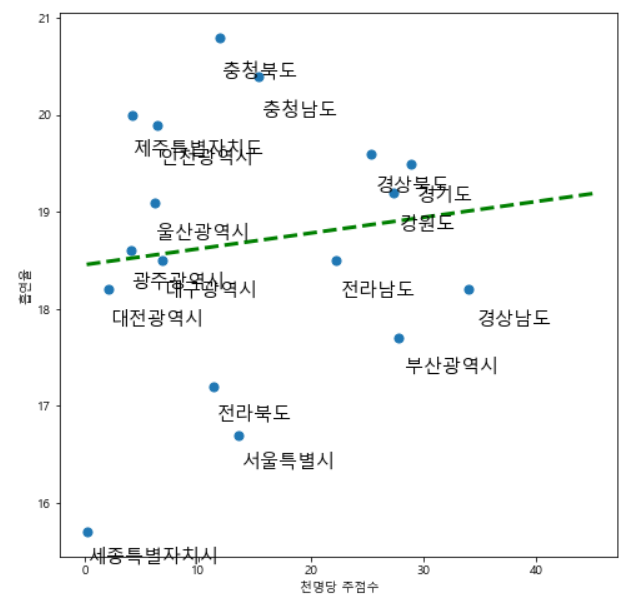
흡연율과 천 명당 주점 수의 관계를 추세선을 통해 확인해볼 수 있다. 상관성이 높은 지역으로는 경기, 경북, 강원 등이다.
drink_corr = corr.drop(['1인당 공원 면적', '흡연율'], axis=1)
drink_corr = drink_corr.drop(['1인당 공원 면적', '흡연율'])
drink_corr
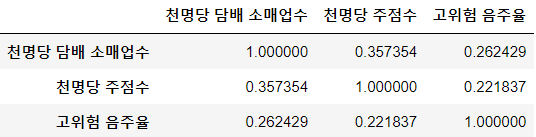
drink_heatmap = sns.heatmap(drink_corr, cbar = True, annot = True, annot_kws={'size' : 18}, fmt = '.2f', square = True, cmap = 'Blues')
drink_heatmap
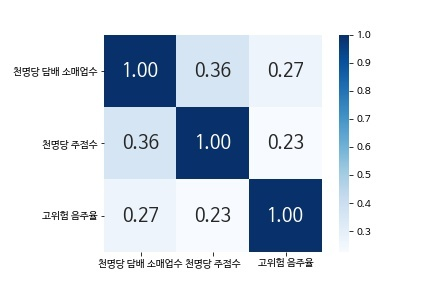
한편 고위험 음주율과 천 명당 담배 소매업체 수, 고위험 음주율과 천 명당 주점 수의 상관계수는 각각 0.27, 0.23으로 약한 양의 상관관계를 보인다.
#고위험 음주율과 천명당 주점 수
fp1 = np.polyfit(merge['천명당 주점수'], merge['고위험 음주율'],1)
f1 = np.poly1d(fp1)
fx = np.linspace(45, 0, 17)
plt.figure(figsize=(8,8))
plt.scatter(merge['천명당 주점수'], merge['고위험 음주율'], s=50)
plt.plot(fx, f1(fx), ls='dashed', lw=3, color='g')
# 텍스트 만들어주기
for n in range(17):
plt.text(merge['천명당 주점수'][n]*1.04, merge['고위험 음주율'][n]*0.99,
merge.index[n], fontsize=15)
plt.xlabel('천명당 주점수')
plt.ylabel('고위험 음주율')
plt.show()

광역시도별로 확인해보면 고위험 음주율과 도시환경의 상관성이 높은 지역은 두 가지 변수 모두 강원, 전남, 경상 지역 등이다.
그렇다면, 1인당 공원 면적은 흡연율과 음주율을 낮추는 변수가 될 수 있을까?
park_corr = corr.drop(['천명당 담배 소매업수', '천명당 주점수', '고위험 음주율'], axis=1)
park_corr = park_corr.drop(['천명당 담배 소매업수', '천명당 주점수', '고위험 음주율'])
park_corr
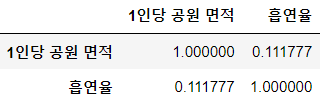
park_heatmap = sns.heatmap(park_corr, cbar = True, annot = True, annot_kws={'size' : 18}, fmt = '.2f', square = True, cmap = 'Blues')
park_heatmap
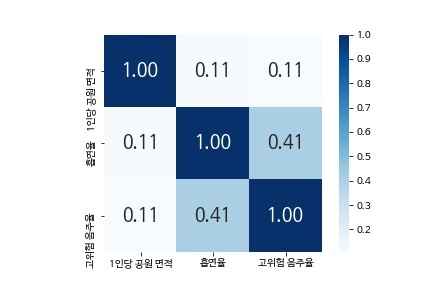
흡연율, 고위험 음주율과 1인당 공원 면적의 상관계수는 모두 0.11 정도로 매우 약한 양의 상관관계를 보인다.
이는 기존의 가정과, 참고자료로 삼은 보고서의 결과와는 반대되는 결과이면서 상관계수가 0.2 이하이기에 이 프로젝트의 선정 기준에는 못 미치는 변수라고 할 수 있다.
3.4 사회경제적 환경 측면의 요인 분석
3.4.1 지도 시각화로 분포 알아보기
이번엔 사회경제적 환경 측면에서 건강행동의 지역 격차를 유발하는 요인을 찾아보겠다. 사용한 변수는 1인당 보험료, 조이혼율, 재정자립도다.
#1인당 보험료
bins = list(social['1인당 보험료'].quantile([0, 0.25, 0.5, 0.75, 1]))
map = folium.Map(location = [36, 127], zoom_start=7)
folium.Choropleth(geo_data = geo_str,
data = social,
columns = ['시도', '1인당 보험료'],
fill_color='Greens',
key_on = 'feature.id',
legend_name = '1인당 보험료',
bins=bins,
reset=True).add_to(map)
map

#조이혼율
bins = list(social['조이혼율'].quantile([0, 0.25, 0.5, 0.75, 1]))
map = folium.Map(location = [36, 127], zoom_start=7)
folium.Choropleth(geo_data = geo_str,
data = social,
columns = ['시도', '조이혼율'],
fill_color='Greens',
key_on = 'feature.id',
legend_name = '조이혼율',
bins=bins,
reset=True).add_to(map)
map
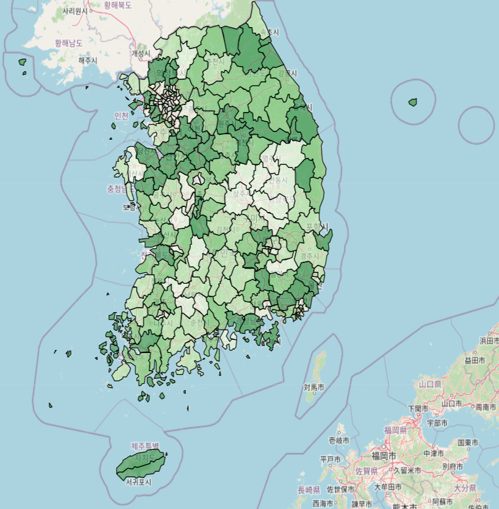
#재정자립도
#재정자립도
bins = list(social['재정자립도(개편후)'].quantile([0, 0.25, 0.5, 0.75, 1]))
map = folium.Map(location = [36, 127], zoom_start=7)
folium.Choropleth(geo_data = geo_str,
data = social,
columns = ['시도', '재정자립도(개편후)'],
fill_color='Greens',
key_on = 'feature.id',
legend_name = '재정자립도(개편후)',
bins=bins,
reset=True).add_to(map)
map
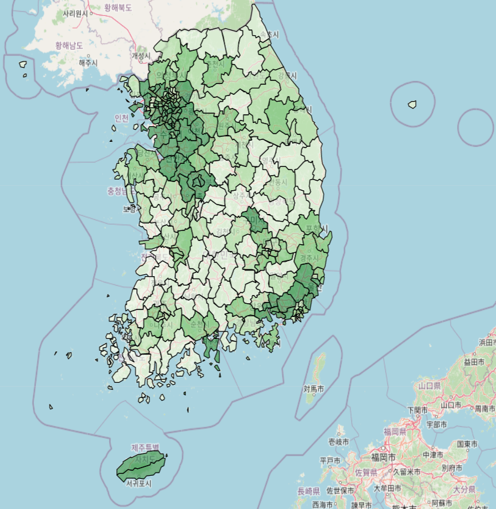
- 재정 자립도 : 재정 수입의 충당 능력을 나타내는 지표로 재정 자립도가 높을수록 재정 운영의 자립 능력이 우수함을 의미한다.
지도상에서 보험료와 재정 자립도는 서울, 경기 등 수도권과 부산 지역, 즉 대도시 위주로 수치가 높은 것을 볼 수 있다. 한편 조이혼율은 경기, 충남, 경남 지역에서 두드러진다.
3.4.2 건강행동과 사회경제적 환경 간의 관계
이 파트에서는 계층과 재정 자립도가 낮을수록, 조이혼율이 높을수록 흡연율과 음주율이 높을 것이라고 가정하고 분석을 진행했다.
social = pd.read_excel('사회 통합.xlsx')
social = social.drop(['보험료','이혼','재정자립도(개편전)'], axis=1)
corr = social.corr(method='pearson')
hierarchy_corr = corr.drop(['인구수', '조이혼율', '재정자립도(개편후)'], axis=1)
hierarchy_corr = hierarchy_corr.drop(['인구수', '조이혼율', '재정자립도(개편후)'])
hierarchy_corr
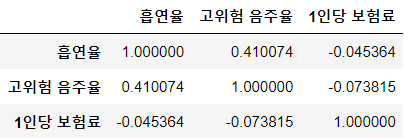
#1인당 보험료(계층)와 건강행동
hierarchy_heatmap = sns.heatmap(hierarchy_corr, cbar = True, annot = True, annot_kws={'size' : 20}, fmt = '.2f', square = True, cmap = 'Blues')
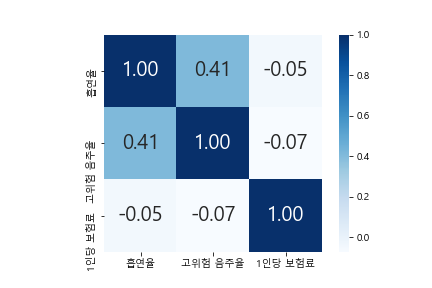
변수 간 상관분석을 한 결과, 1인당 보험료와 흡연, 음주율의 상관계수는 각각 -0.05, -0.07로 상관관계가 거의 없다고 할 수 있다.
divorce_corr = corr.drop(['인구수', '1인당 보험료', '재정자립도(개편후)'], axis=1)
divorce_corr = divorce_corr.drop(['인구수', '1인당 보험료', '재정자립도(개편후)'])
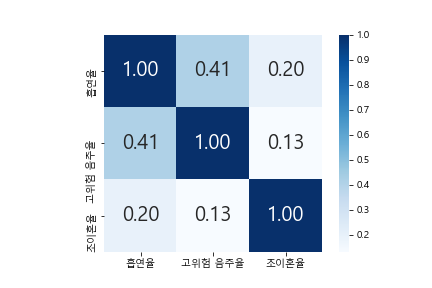
divorce_corr
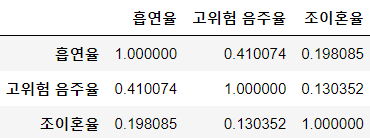
#조이혼율과 건강행동
divorce_heatmap = sns.heatmap(divorce_corr, cbar = True, annot = True, annot_kws={'size' : 20}, fmt = '.2f', square = True, cmap = 'Blues')
fp1 = np.polyfit(merge2['조이혼율'], merge2['흡연율'],1)
f1 = np.poly1d(fp1)
fx = np.linspace(2.8, 1.5, 17)
plt.figure(figsize=(8,8))
plt.scatter(merge2['조이혼율'], merge2['흡연율'], s=50)
plt.plot(fx, f1(fx), ls='dashed', lw=3, color='g')
for n in range(17):
plt.text(merge2['조이혼율'][n]*1.008, merge2['흡연율'][n]*0.995,
merge2.index[n], fontsize=11)
plt.xlabel('조이혼율')
plt.ylabel('흡연율')
plt.show()

조이혼율과 흡연율의 상관계수는 0.2로, 특히 충청 지역, 제주, 인천 지역이 상관성이 높았다. 반면 조이혼율과 고위험 음주율은 상관성이 거의 없었다.
finance_corr = corr.drop(['인구수', '1인당 보험료', '조이혼율'], axis=1)
finance_corr = finance_corr.drop(['인구수', '1인당 보험료', '조이혼율'])
finance_cor

#재정자립도와 건강행동
finance_heatmap = sns.heatmap(finance_corr, cbar = True, annot = True, annot_kws={'size' : 20}, fmt = '.2f', square = True, cmap = 'Blues')
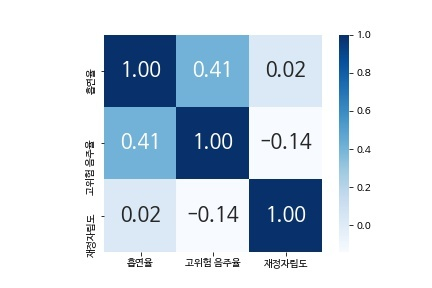
재정자립도와 건강행동도 마찬가지로 상관성이 매우 낮은 결과가 도출되었다.
4. 결론
4.1 결과 요약
결론적으로 이 분석에서는 먼저 건강 행동의 지역 격차를 확인했다. 두 건강 행동 모두 충청, 강원 지역의 수치가 높은 데 비해 세종, 서울, 전라권은 비교적 낮다는 공통점을 가진다.
또한 지역격차에 관련된 사회적 결정요인을 찾아보았다. 분석 결과, 흡연율의 지역 간 변이와 관련된 변수는 천 명당 주점 수와 조이혼율이고, 고위험 음주율의 지역 간 변이와 관련된 변수는 천 명당 주점 수와 천 명당 담배 소매업체 수였다.
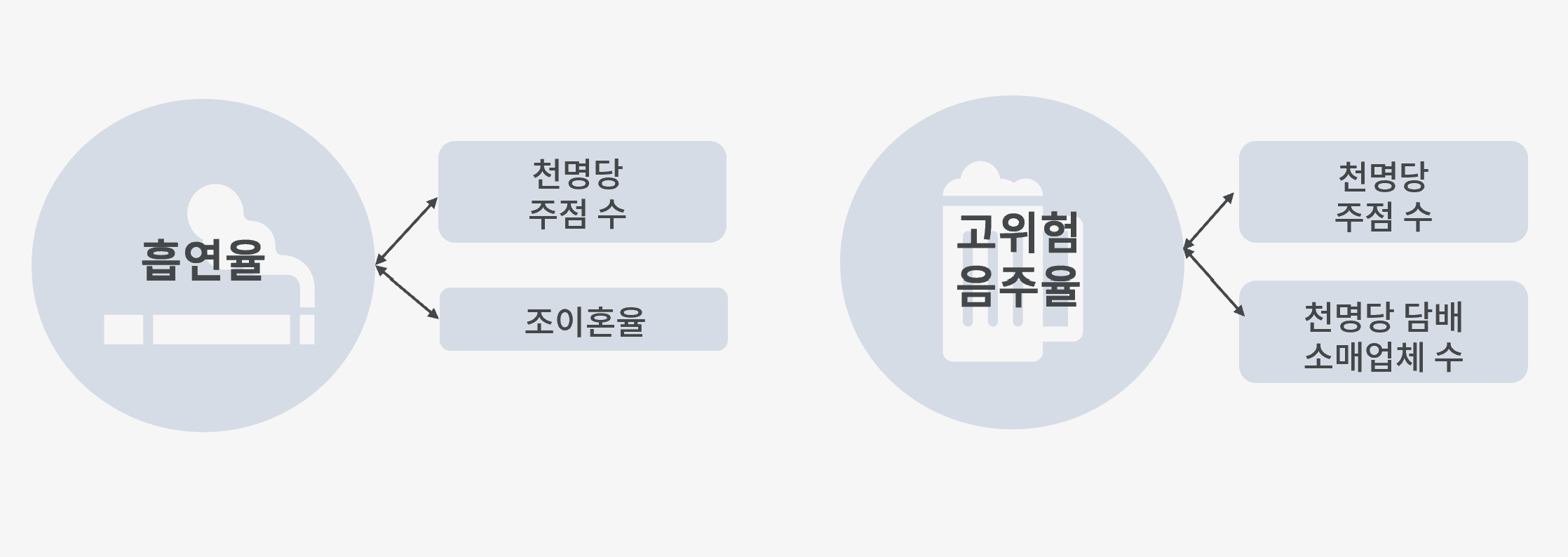
4.2 건강 행동 격차 축소 방안
더 나아가 이 분석에 기반하여 지역 간 건강행동의 격차를 축소할 방안을 고민해 볼 수 있었다. 지역적 특성을 고려한 정책과 지자체 중심의 보건복지 사업이 그 해결법이라고 할 수 있다.
전체 국민을 대상으로 건강증진 캠페인을 펼치기보다는 지역의 물리적, 사회경제적 환경을 고려해 특정 집단이나 지역을 겨냥해 정책을 펼치는 것이 더 효과적일 것이다. 그러기 위해서는 예산과 사업 수행 등의 과정에서 지자체의 자율성을 높이는 방향으로의 전환이 필요하다고 판단된다.
그리고 분석 결과를 적용하여 나름대로의 해결방안을 생각해 본 결과, 흡연율이 높고 천 명당 주점 수와의 상관관계가 뚜렷한 경상지역은 절주 사업을 시행하거나, 사람들이 음주 이외의 활동이나 취미로 눈을 돌리게 하는 정책을 시행할 수 있다.
또한 경기지역은 흡연율과 조이혼율의 경향이 강한 지역으로, 지자체에서 금연 장려 사업을 실시해 흡연자들이 금연을 결심하도록 지속적인 관리를 제공하는 정책을 펼칠 수 있다. 또는 이혼율이 흡연과 상관관계가 높다는 점을 고려해 이혼한 개인, 한 부모 가정 등을 대상으로 복지 지원 사업을 시행할 수도 있을 것이다.
4.3 한계 및 제언
- 분석을 진행했던 모든 변수와 건강행동의 상관계수가 0.3 이하로, 더 유의미한 요인을 찾아내지 못한 것이 아쉽다. 또한 지역 격차의 요인을 찾아내는 데 집중하다 보니 가설과 다른 결과가 나온 변수들에 대한 설명이 부족했다.
- 데이터 분석을 넘어 지자체별로 건강행동과 관련된 어떤 정책들이 시행되고 있고, 어떤 정책이 필요한지에 대한 조사의 필요성을 말하고 싶다. 이를 통해 건강행동 취약 지역을 좀 더 세밀하게 필터링하여 더 효과적인 보건 정책을 고안해 낼 수 있을 것으로 기대한다.
출처
- 김동현, 2010, ‘2008년 지역사회건강조사 자료를 이용한 지역 간 건강행태 변이요인에 대한 분석연구
- 보건복지부, “흡연,음주 감소했지만 지역 간 격차 해소 노력 필요“, 대한민국 정책브리핑, 2020.05.21,
- 류장훈, “최근 4년간 국민건강지표 악화… 지역별 격차는 여전“, 청년의사, 2012.04.18,
- 이경아, “지난해 흠연 음주 줄었지만 활동량 줄어들어 지역간 건강관리 커",매일경제, 2021.04.01,