한국어 형태소 분석기 비교 (지도학습기반)
by 이정윤
🌊 Introduction
한국어 문장의 형태소 분석을 시도하면, 언제나 영어에 비해 후처리가 까다롭다는 것을 느낀다. 많은 형태소 분석기가 등장하고 있음에도, 말뭉치의 특성에 따라 조금씩 다른 성능을 보이므로 후처리를 가장 적게 해줄 수 있는 형태소 분석기를 선택하는 것이 중요하다. 적합한 형태소 분석기는 소요시간이 적게 걸리는 것과 형태소 분석의 정확도가 높은 것이 중요한 요소이다. 이때, 말뭉치의 종류(전문단어의 사용, 한자 및 특수어휘 등)에 따라 성능의 차이가 조금씩 발생할 가능성이 있음으로 여러 형태소 분석기의 성능에 대한 비교가 필요하다. 따라서 이버 실습은 어떤 형태소 분석기를 사용할 지 결정하기 위해 형태소 분석기의 속도와 정확도 부분에 대한 비교를 진행한다. 향후 목표는 한국어 형태소 분석을 진행할 때마다 사용할 수 있는 완전한 함수를 정리하는 것이다.
사용한 형태소 분석기들은 C++, 자바 등 각각 다른 환경에서 만들어지기도 했고, 윈도우 환경에서는 제공하지 않는 경우도 있다. 따라서 로컬에서 사용하기 위해서는 설치경로 설정과 컴파일러 설치 등 까다로운 조건이 많으므로 Google Colab Notebook을 사용하여 실습을 진행한다. 실습한 전체 코드는 이 링크 확인할 수 있다.
참고도서: 한국어임베딩(이기창, 2019)
🌊 Before we start
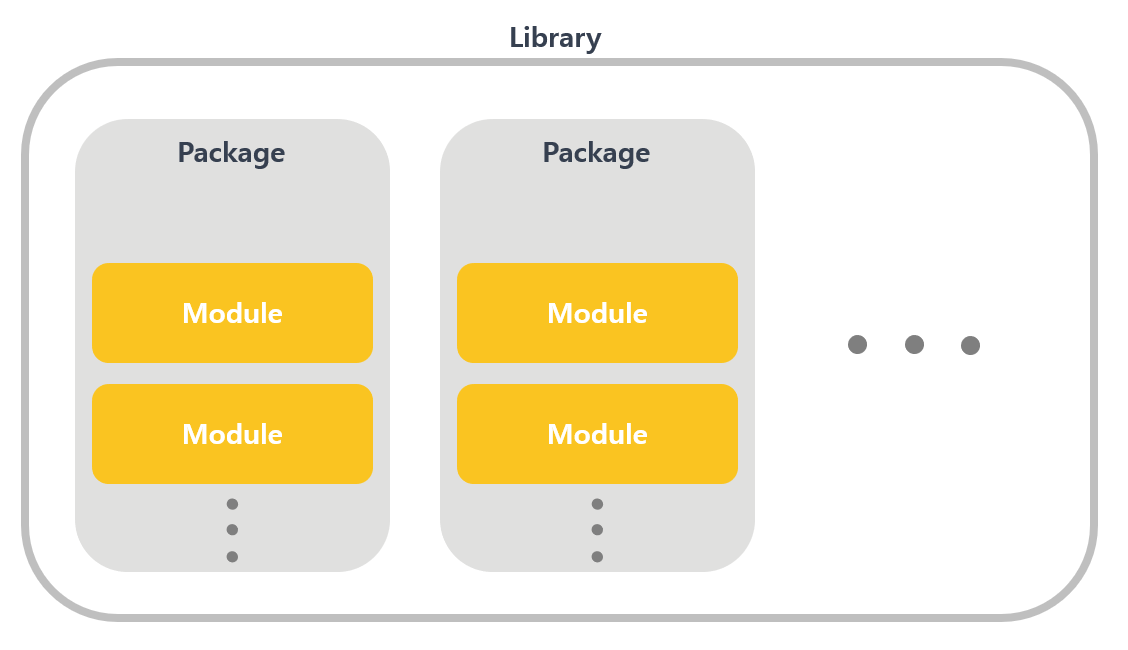
모듈, 패키지, 라이브러리의 차이는?
- 모듈: 모듈은 특정 기능들(함수, 변수, 클래드 등)이 구현되어 있는 파이썬 파일(.py)을 의미한다. import로 불러오는 것들은 모듈!
- 패키지: 특정 기능과 관련된 여러 모듈들을 하나의 상위 폴더에 넣어 놓은 것을 패키지라고 한다. 패키지 안에 여러가지 폴더가 더 존재할 수 있음.
- 라이브러리: 여러 모듈과 패키지를 묶어 라이브러리라고 한다. 파이썬을 설치할 때 기본으로 설치되는 '표준라이브러리' (혹은 내부라이브러리)와 외부에서 개발한 모듈과 패키지를 묶은 '외부라이브러리'가 있다.
라이브러리와 패키지는 사용하는 언어에 따라서 혼용되기도 하지만, 일반적으로는 모듈⊂패키지⊂라이브러리 의 관계를 갖는다고 정리할 수 있다.
예를 들어 from konlpy.tag import Okt 는 konlpy라는 패키지 안의 tag라는 디렉토리(directory. 파일을 묶어주는 개념)에서 Okt라는 모듈을 실행해라! 라는 의미로 해석할 수 있다.
🌊사용한 말뭉치
사용한 말뭉치는 문화재청 에서 제공하는 API를 통해 다운받은 '문화재검색 상세'데이터 중 '내용' 부분이다. 한국어 문장을 분석할 때, 명사를 추출하는 경우가 많으므로, 명사 추출기준으로 함수 설정하였다.
import pandas as pd
df=pd.read_excel('heritage-spec.xlsx')
df=df[['문화재명(국문)', '내용']]
df.head()
다음과 같은 df를 정리해줄 수 있다.

🌊 지도학습 기반 형태소 분석
지도학습 기반 형태소 분석은 문장을 토큰화할 때에 언어학 전문가들이 태깅한 형태소 분석 말뭉치로 부터 학습된 태깅을 사용하는 것이다. (지도학습: 정답이 있는 데이터의 패턴을 학습해 모델이 정답을 맞도록 하는 기법) KoNLPy 패키지의 여러 모듈과 Khaiii는 모두 이미 학습된 모델을 기반으로 갖고 있어 토큰화하고 싶은 문장을 넣어주면 정답 패턴에 맞게 토큰화하여 출력한다.
1) KoNLPy
KoNLPy는 아래 다섯 개의 오픈소스 형태소 분석기를 파이썬 환경에서 사용할 수 있도록 한 한국어 자연어처리 패키지이다.
- Kkma
- Okt
- hannanum
- Mecab (Not supported on MS Windows)
- Komoran (
from konlpy.tag import Komoran으로 실행했을 때 Java에러가 발생함. 해결하지 못하여 PyKomoran으로 진행)
KoNLPy 공식 사이트에서는 각 형태소 분석기 간의 로딩, 실행 시간과 성능을 문자의 개수에 따라 비교하여 정리해두었다. (참고)
참고블로그: Mecab 설치 , PyKomoran 설치 , 코드실행시간측정 , KoNLPy tag class
- 설치하기
KoNLPy를 설치하는 과정에 대한 부가적인 설명은 생략한다.
###for konlpy
!apt-get update
!apt-get install g++ openjdk-8-jdk python-dev python3-dev
!pip3 install JPype1-py3
!pip3 install konlpy
!JAVA_HOME="C:\Program Files\Java\jdk-13.0.2"
###for mecab
%%bash
apt-get update
apt-get install g++ openjdk-8-jdk python-dev python3-dev
pip3 install JPype1
pip3 install konlpy
###환경변수설정 (for mecab)
%env JAVA_HOME "/usr/lib/jvm/java-8-openjdk-amd64"
###Mecab 설치
%%bash
bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
pip3 install /tmp/mecab-python-0.996
###for komoran
!pip install PyKomoran
- 모듈 (형태소분석기) 설치하기
앞서 언급했듯 from konlpy.tag import Komoran으로 실행했을 때 Java에러가 발생했다. 이를 해결하지 못하여 PyKomoran설치하여 진행하였다.
from konlpy.tag import Kkma, Komoran, Hannanum, Okt
from konlpy.tag import Mecab
from PyKomoran import Komoran, DEFAULT_MODEL
okt=Okt()
kkma=Kkma()
hannanum = Hannanum()
komoran = Komoran(DEFAULT_MODEL['FULL'])
mecab = Mecab()
- 소요시간 확인 함수 만들기
각 형태소 분석기에 따라 명사를 추출하는데 걸리는 시간을 비교해보기 위한 함수를 설정한다. 결과는 아래 Khaiii와 한 번에 확인해보자.
import time
def time_use(a,b):
start = time.time()
for i in range(0, 353): #문서의 형태, 크기에 따라서 다르게 설정하기
contents=df['내용'].loc[i] #말뭉치 설정
nouns=a.nouns(contents)
globals()['Var_{0}{1}'.format(b, i)]=nouns
end = time.time()
total_time=(f"{end - start:.5f} sec")
print('{0} ==> {1}'.format(a ,total_time))
2) Khaiii
Kakao에서 만든 Khaiii는 MS Window를 지원하지 않는다. 그러나 아래의 코드로 코랩에서 설치하면 정상적으로 사용할 수 있었다. (로컬에 설치하기 위해서는 컴파일러 설치가 필요하다.) 다운받는 데 약 10분 정도 소요된다.
참고블로그: 코랩에 Khaiii설치하기
- 설치하기
Khaiii 설치에 대한 부가적인 설명은 생략한다. (공식 홈페이지와 위 블로그 참고)
!git clone https://github.com/kakao/khaiii.git
!pip install cmake
!mkdir build
!cd build && cmake /content/khaiii
!cd /content/build/ && make all
!cd /content/build/ && make resource
!cd /content/build && make install
!cd /content/build && make package_python
!pip install /content/build/package_python
- 모듈 설치하기
from khaiii import KhaiiiAp
khaiii = KhaiiiApi()
- 소요시간 확인 함수 만들기
def time_use2(a):
start = time.time()
for i in range(0, 10): #문서의 형태, 크기에 따라서 다르게 설정하기
contents=df['내용'].loc[i] #말뭉치 설정
nouns = []
for word in khaiii.analyze(contents):
for morph in word.morphs:
if morph.tag in ['NNG', 'NNP', 'SN']:
nouns.append(morph.lex)
globals()['Var_khaiii{}'.format(i)]=nouns
end = time.time()
total_time=(f"{end - start:.5f} sec")
print('{0} ==> {1}'.format(a ,total_time))
3) KoNLPy, Khaiii 한번에 비교하기
3-1) 소요시간 비교
앞서 설정한 함수를 사용하여 각 형태소 분석기가 명사를 추출하는데 소요되는 시간을 확인해본다. 해당 시간은 heritage-spsc의 국보1호 부터 353호 까지의 내용 중 명사 토큰을 추출하는 시간이다.
time_use(okt,'okt')
time_use(hannanum, 'hannanum')
time_use(kkma, 'kkma')
time_use(komoran, 'komoran')
time_use(mecab, 'mecab')
time_use2(khaiii)
결과는 다음과 같이 Mecab > Khaiii > Komoran > Okt > Hannanum > Kkma 순으로 속도가 빠르다.

(데이터 양이 많아질수록 hannanum보다 Okt가 훨씬 빨리졌다. 또한 실행 할 때마다 형태소 분석기 속도가 약간의 차이를 보였다.)
3-2) 성능비교 (명사 토큰 추출 결과)
소요시간도 중요하지만, 가장 중요한 것은 토큰이 올바르게 추출되었는지에 대한 정확도이다. 정확도를 확인하기 위해서는 추출된 토큰을 데이터 프레임으로 만들어준 뒤, 하나씩 확인해주는 방법을 택했다.
#KoNLPy 결과
konlpy_dic = { 'okt' : Var_okt1, 'hannanum' : Var_hannanum1, 'kkma' : Var_kkma1 , 'komoran': Var_komoran1, 'mecab' : Var_mecab1}
konlpy_df= pd.DataFrame.from_dict(konlpy_dic, orient='index')
konlpy_df = konlpy_df.transpose()
#Khaiii 결과
khaiii_columns=['khaiii']
khaiii_df=pd.DataFrame(Var_khaiii1, columns=khaiii_columns)
###두 결과 합치기
total_tokens=pd.concat([konlpy_df, khaiii_df], axis=1)
#to_excel('명사토큰비교.xlsx')
total_tokens
아래의 결과는 국보2호 하나의 내용을 토큰화한 결과이다.

okt는 114개, hannanum은 102개, kkma는 109개, komoran는 89개, mecab은 117개, 그리고 khaiii는 116개의 토큰으로 문장을 쪼개주었다. 가장 세세하게 명사를 추출한 건 Mecab(117), Khaiii(116)이고 Komoran(89)은 가장 러프하게 추출했다. 적합한 형태소 분석기는 이 데이터 프레임을 보고 각 단어를 하나하나 비교하여 선택해야 한다. 예를 들어, '걸작품'이라는 단어를 하나의 단어로 인식한 Khaiii가 '걸'과 '작품'으로 인식한 Mecab 보다 더 나은 형태소 분석을 했음을 알 수 있다. 이와 같이 모든 단어들을 비교해보고 가장 적합한 형태소 분석기를 선택하는 과정이 다소 주관적일 수는 있으나, 사용 목적 및 최종 결과물 형태에 따라 결정하면 된다.
🌊 Future tasks
이번 실습에서는 임베딩 이전 작업인 전처리 단계 중
- 데이터 확보 (말뭉치)
- 지도 학습 기반 형태소 분석
- KoNLPy
- Khaiii
에 대해서 진행하였다. 지도학습 기반 패키지 중 아직 시도해보지 않은 KoalaNLP에 대한 추가적인 속도, 성능 비교가 필요하다. 또한 지도 학습 기반 형태소 분석 다음에는 스스로 데이터의 패턴을 학습하게 하면서 형태소를 분석하는비지도 학습 형태소 분석을 진행해보려 한다.
- 비지도 학습 형태소 분석
- soynlp
- Google sentencepiece