스크래이피 톺아보기 1
by 김윤진
안녕하세요 여러분! 저는 지금까지 배웠던 scrapy를 정리하는 시간을 가져보려고 합니다.
지금까지 삼 주동안 11번가 웹사이트의 상품들을 크롤링하는 작업을 했습니다. 저는 이 과정을 네 단계로 나누어 보려고 합니다.
1. scrapy 설치 및 scrapy shell 사용 익히기
그럼 이번주는 우선 1. scrapy 설치 및 scrapy shell 사용 익히기에 대해서 알아보도록 하겠습니다. scrapy를 다운 받을 수 있는 웹사이트에서는 scrapy에 대해서 "Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing."라고 설명하고 있습니다. 단순히 말해 웹 크롤링을 유용하게 할 수 있도록 돕는 프로그램이죠. 크롤링을 쉽게 하기 위해 scrapy를 설치해 봅시다!
1) scrapy 설치
scrapy를 설치하는 방법은 여러가지입니다.
- scrapy 웹사이트에서 다운로드 받을 수 있는 방법이 있습니다.
- 더 쉽고 편리한 방법으로는 terminal을 사용하는 겁니다. 편리하게 터미널에
pip install scrapy를 쳐주시면 됩니다.

2) scrapy shell 사용 익히기
scrapy shell이 무엇인지 구글링해보면 "The Scrapy shell is an interactive shell where you can try and debug your scraping code very quickly, without having to run the spider"이라고 나옵니다. 즉, 페이지 전체를 크롤링하지 않고 원하는 명령어만 입력해주면 해당 부분에 대한 크롤링 데이터를 출력해줍니다. 때문에 한 페이지에서 여러가지를 한꺼번에 크롤링할 때 scrapy shell을 통해 한 명령씩 입력해보고 오류가 뜨지는 않는지, 제대로 실행되는지 확인해볼 수 있겠죠?
scrapy shell을 여는 방법은 terminal에 **scrapy shell "크롤링할 웹 주소"**를 입력하는 것입니다. 저는 저희가 4주차 과제로 했었던 지마켓 베스트 상품 주소로 예시를 들어보겠습니다.
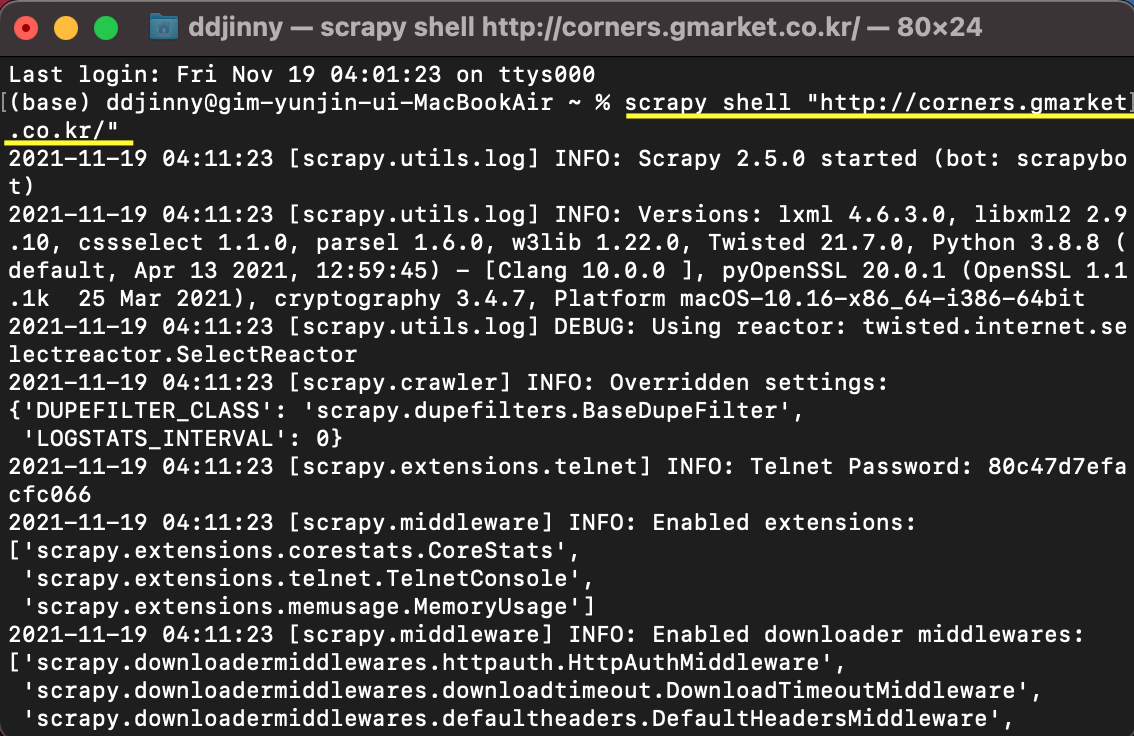
짜잔! 아주 쉽게 원하는 웹사이트의 scrapy shell 창을 열 수 있습니다!