코로나19가 사이버 범죄에 미친 영향 분석
by 김정민, 최예지
1. 분석 목적
우리는 21년 현재, 코로나19 시대에 살고 있습니다. 코로나19 시대는 우리에게 많은 변화를 가져다 주었습니다.
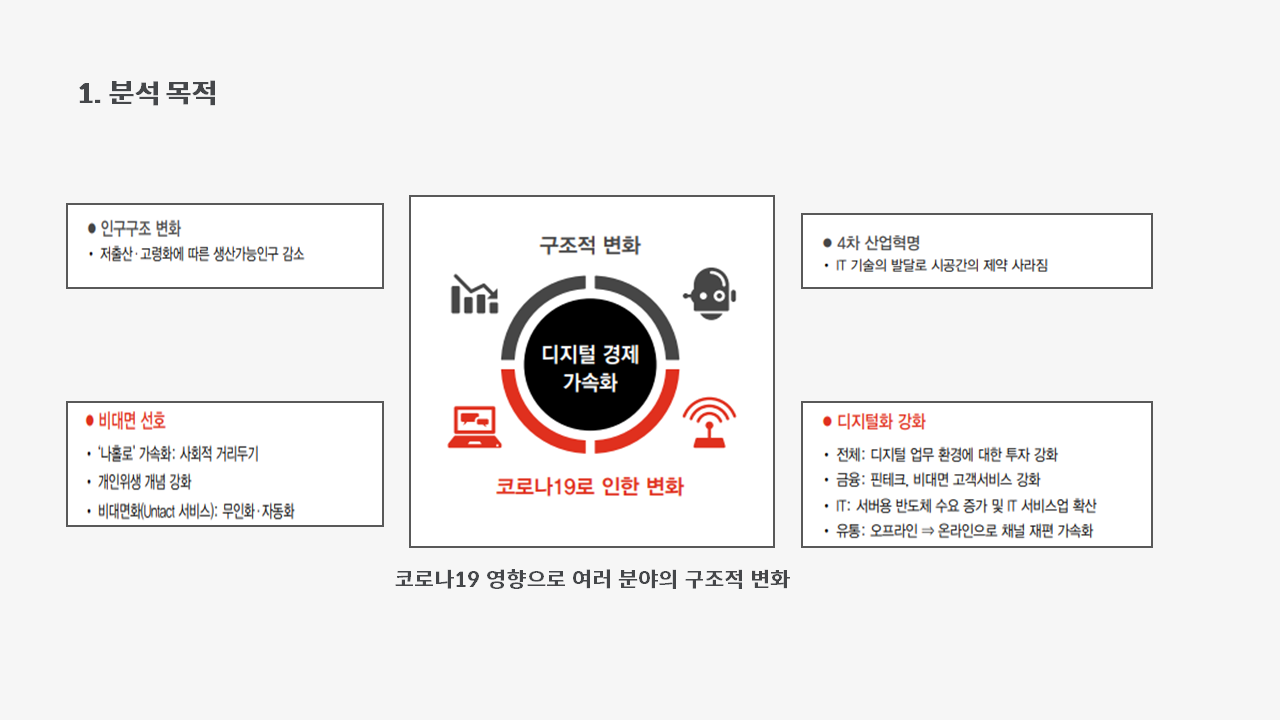
- 인구구조의 변화: 고질적 사회 문제였던 저출산과 고령화는 가속화 되었습니다.
- IT기술의 발달: 시공간의 제약이 사라졌고, 자연스레 비대면의 선호도도 증가했습니다.
- 디지털화 강화: 디지털 가속화가 사회 전반적으로 시작되었습니다. 이커머스 시장은 급속도로 발전하였고, 무인 가게들도 많이 늘어났습니다.

그 중에서 저희는 디지털 분야에 관심을 가졌습니다.
과연 코로나로 인해 디지털이 과속화 되었다는 점이 우리에게 이롭기만 할지, 나쁜 영향은 없었는지, 만약 나쁜 영향이 있다면 어떤 것들이 있을지 궁금했습니다.
 여러 디지털의 악영향 중에서 사이버 범죄를 떠올렸고, 그렇게 사이버 범죄와 코로나 19의 관계에 대해 분석하게 되었습니다.
여러 디지털의 악영향 중에서 사이버 범죄를 떠올렸고, 그렇게 사이버 범죄와 코로나 19의 관계에 대해 분석하게 되었습니다.
2. 사이버 범죄란?
사이버 범죄란, 컴퓨터, 통신, 인터넷 등을 악용하여 사이버 공간에서 행하는 모든 범죄를 말합니다.
대표적으로 우리가 흔히 알고 있는 스팸, 해킹, 사이버 금융 사기, 사이버 도박, 피싱 등이 사이버 범죄에 해당합니다.
3. 데이터 선정
코로나가 사이버범죄에 영향을 줬는지 알기 위해서는 코로나의 심각성을 잘 나타내주는 확진자 수와 사이버 범죄 지표인 경찰청에서의 사이버 범죄 통계 현황이라는 통계표와 비교해보고자 했습니다.
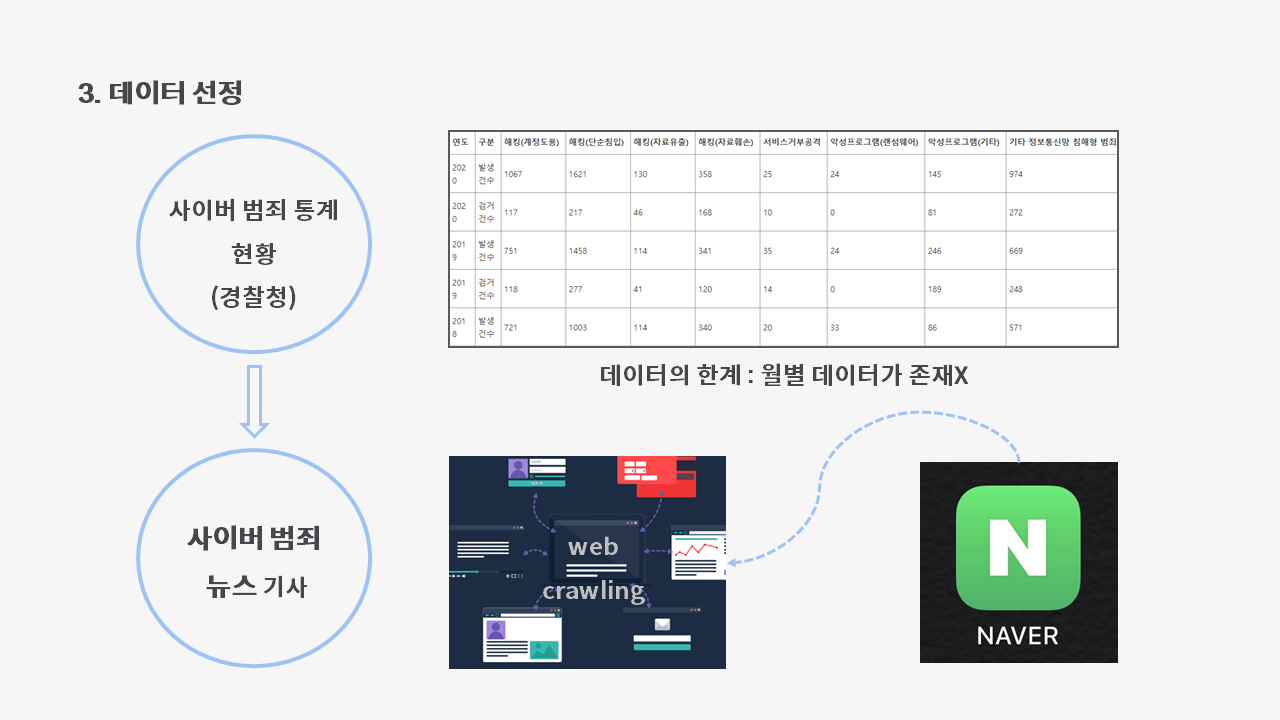
그러나 월별로 데이터가 있는 확진자 수와 달리, 사이버 범죄 통계는 연도별로만 그 수치가 나타나 있어 비교에 어려움이 있었습니다.
그래서 경찰청의 데이터를 이용하는 대신, 네이버 기사를 크롤링해서 사이버 범죄 관련 키워드를 가진 뉴스 기사 수를 수치화 했습니다.
그렇게 선정된 데이터는 다음과 같습니다.

- 분석 기간: 19년 하반기 VS 20년 하반기
코로나의 영향을 받아 사이버 범죄가 있기까지 그리고 그 범죄가 기사화 되기까지, 시간이 어느 정도 필요하겠죠? 그래서 19년도와 20년도 모두 하반기인 7월부터 12월까지로 기간을 설정했습니다.
- 키워드
경찰청에서 정의한 <정보통신망 이용 범죄>를 기준으로 정했습니다.
- 시각화
- 코로나19 시대 전후(19년 하반기 VS 20년 하반기) 사이버 범죄 기사 수를 matplotlib을 이용하여 막대그래프로 시각화하였습니다.
- 코로나 확진자 수와 사이버 범죄 기사 수의 관계를 matplotlib을 이용하여 막대, 선그래프로 시각화하였습니다.
- 19년 하반기 대비 20년 하반기 눈에 띄는 키워드를 wordcloud를 통해 분석하였습니다.
4-0. 데이터 가공
분석하기 위해서는 데이터 있어야겠죠?
먼저 데이터를 분석하기 쉽게 가공하는 과정을 거쳐보도록 하겠습니다.
-
뉴스 기사 크롤링 과정
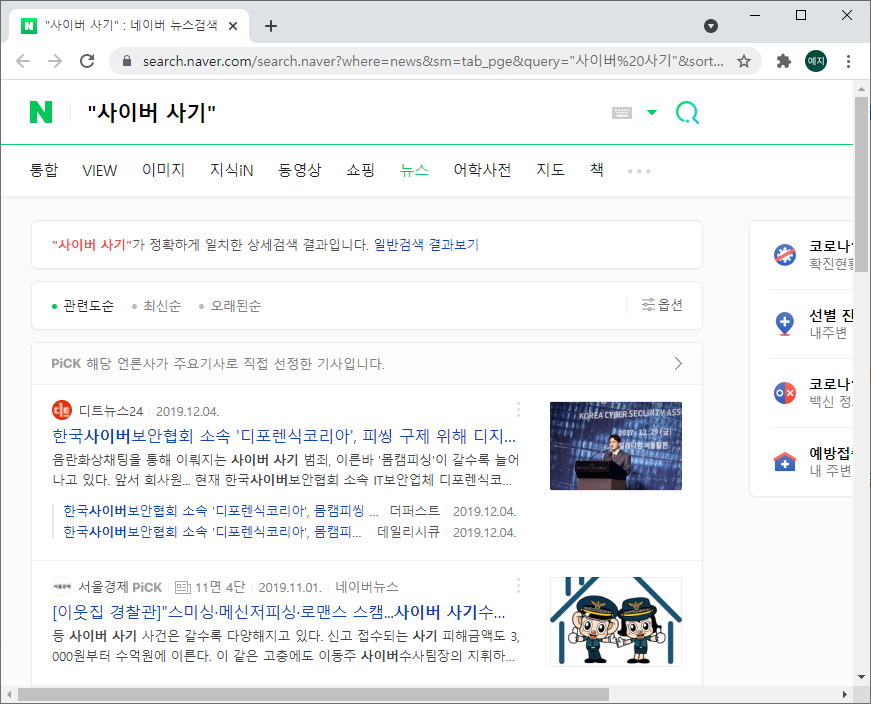
- 먼저 네이버에 키워드를 검색한 후 뉴스를 클릭합니다.
정확하게 키워드와 일치한 검색 결과를 얻기 위해서는 "쌍따옴표"를 붙여야 합니다.
-
옵션에서 기간을 설정해줍니다.
-
해당 검색 결과의 마지막 페이지가 몇 페이지인지 확인해줍니다.

-
주소 창의 링크를 복사합니다.
-
앞서 알아낸 마지막 페이지의 숫자와 페이지 주소를 이용하여 다음과 같이 코드를 작성하면, 작성 일시, 기사 제목, 기사 주소가 담긴 데이터 프레임을 만들 수 있습니다.
# 키워드: 사이버 사기 # 기간: 19년 7월부터 12월까지 start = 1 result_19 = pd.DataFrame() #두번째 반복부터는 빼줘야 함. 그렇지 않으면 계속해서 초기화됨. for i in range (5): # 마지막 페이지의 숫자 url = 'https://search.naver.com/search.naver?where=news&sm=tab_pge&query=%22%EC%82%AC%EC%9D%B4%EB%B2%84%20%EC%82%AC%EA%B8%B0%22&sort=0&photo=0&field=0&pd=3&ds=2019.07.01&de=2019.12.31&cluster_rank=13&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so:r,p:from20190701to20191231,a:all&start='+ format(start) # 복사한 링크 끝에 적힌 "all&start=41"에서 숫자 "41"을 빼고 붙여넣기 headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36', 'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'} response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, 'lxml') news_title = [title['title'] for title in soup.find_all('a', attrs={'class':'news_tit'})] # 기사 제목 news_url = [ url['href'] for url in soup.find_all('a', attrs={'class':'news_tit'}) ] # 기사 url dates = [ date.get_text() for date in soup.find_all('span', attrs={'class':'info'})] # 기사 작성일 news_date = [] for date in dates: if re.search(r'\d+.\d+.\d+.', date) != None: # 기사 작성일 정제 news_date.append(date) df = pd.DataFrame({'기사작성일':news_date,'기사제목':news_title,'기사주소':news_url}) result_19 = pd.concat([result_19, df], ignore_index=True) start += 10 result_19
- 위 과정을 필요한 만큼 반복합니다. 저희는 6개의 키워드를 두 기간으로 설정하여 검색해야 하기 때문에 총 12번 반복했습니다.
- 열심히 노가다를 했는데 데이터가 날아가면 매우 슬프겠죠? ಥ_ಥ
다음과 같이 코드를 작성하여 CSV파일로 저장해줍니다.
#19년 하반기 파일 저장
result_19.to_csv('2019년 하반기 사이버범죄 기사.csv', sep=',', encoding='utf-8')
4-1. 코로나19 시대 전후 사이버 범죄 기사 수 비교
우선, 19년도와 20년도 하반기의 사이버 범죄율에 변화가 있는지 확인해보도록 하겠습니다.
저희는 비교를 위해 막대 그래프로 시각화 해보았습니다.
코드는 다음과 같습니다.
#19년 하반기 파일 불러오기
df_19 = pd.read_csv('2019년 하반기 사이버범죄 기사.csv',index_col=0,encoding='utf-8')
df_19.head()
#20년 하반기 파일 불러오기
df_20 = pd.read_csv('2020년 하반기 사이버범죄 기사.csv',index_col=0,encoding='utf-8')
df_20.head()
#'기사작성일' 칼럼을 datetime으로 바꿔주기
df_19['기사작성일']=pd.to_datetime(df_19['기사작성일'])
df_20['기사작성일']=pd.to_datetime(df_20['기사작성일'])
df_19.rename(columns = {'기사작성일' : '일자'}, inplace = True)
df_20.rename(columns = {'기사작성일' : '일자'}, inplace = True)
#일자 칼럼에서 월만 뺀 칼럼 생성, 칼럼순서 바꿔주기
df_19['월'] = df_19['일자'].dt.strftime('%m')
df_19 = df_19[['일자','월','기사제목','기사주소']]
df_19.head()
# 날짜 데이터를 숫자데이터로 바꾸기
df_19['월'] = pd.to_numeric(df_19['월'])
df_20['월'] = pd.to_numeric(df_20['월'])
# 막대 그래프
labels = ['7월','8월','9월','10월','11월','12월']
x=np.arange(len(labels))
width = 0.3
fig, axes = plt.subplots()
axes.bar(x-width/2, df_19_month['일자'], width, align='center', color='darkgreen',alpha=0.5 )
axes.bar(x+width/2, df_20_month['일자'], width, align='center', color='#e35f62',alpha=0.5 )
plt.xticks(x)
axes.set_xticklabels(labels, fontsize=15)
plt.yticks(fontsize=15)
plt.xlabel('월', fontsize=15)
plt.ylabel('기사 수', fontsize=15)
plt.title('19년,20년 하반기 사이버범죄 기사 수', fontsize=15)
plt.grid(True, axis='y')
plt.legend(['19년','20년'], fontsize=15)
plt.show()
이렇게 코드를 쓰면!!!
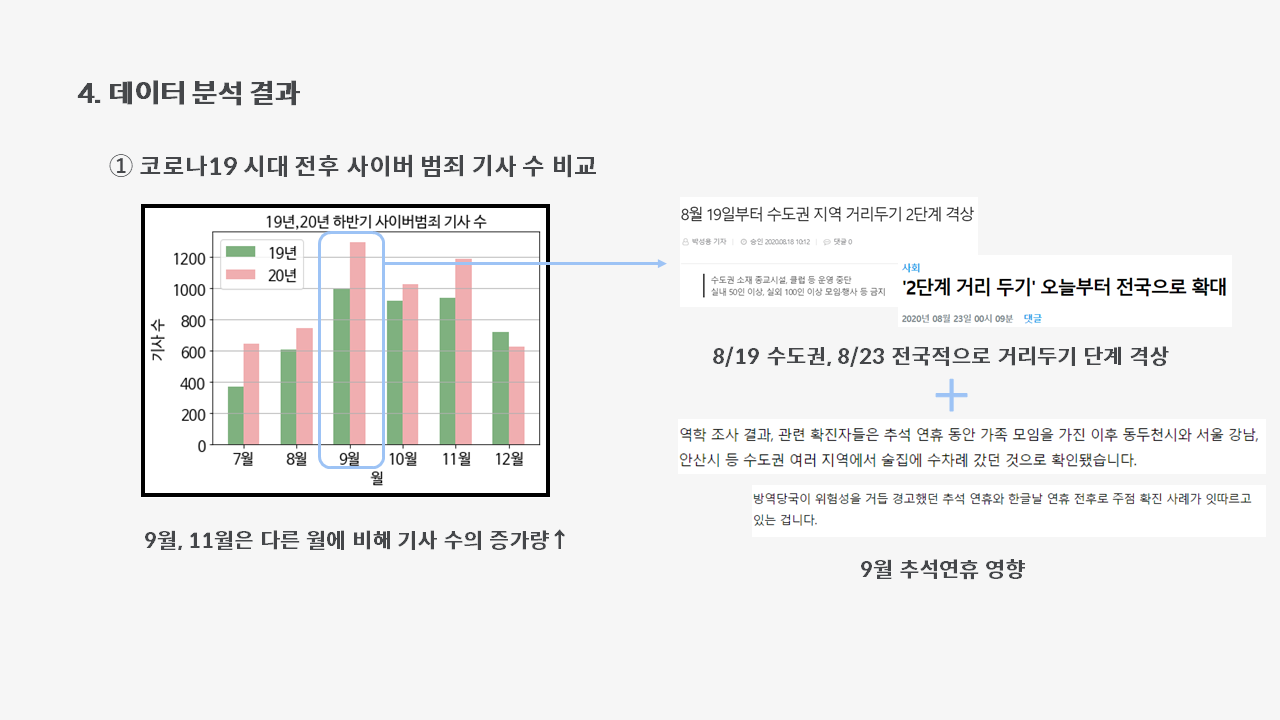
왼쪽과 같은 막대그래프가 예쁘게 그려집니다악😆
그래프를 보면, 9월과 11월이 다른 월에 비해 19년도와 20년도의 차이가 크다는 것을 알 수 있습니다.
9월의 경우, 8월의 거리두기 단계 격상되어 집합 금지 조치가 시행되었다는 것이 영향이 있었던 것으로 보입니다. 그로 인해 소상공인들은 막대한 경제적 난황을 겪었고, 이런 상황에서 맞이한 9월의 추석 연휴는 범죄자들이 범행하기에 적절한 기회가 되었을 것입니다.
이와 관련한 이론으로, 이창무의 박수이론이 있습니다.

"박수도 손뼉이 맞아야 칠 수 있듯, 범죄도 동기와 기회가 모두 있어야 일어난다"
따라서, 9월의 범죄 증가는 경제 악화로 생긴 범죄의 동기와 추석 연휴라는 기회가 맞아 떨어지면서 생긴 현상으로 볼 수 있습니다!!🤔
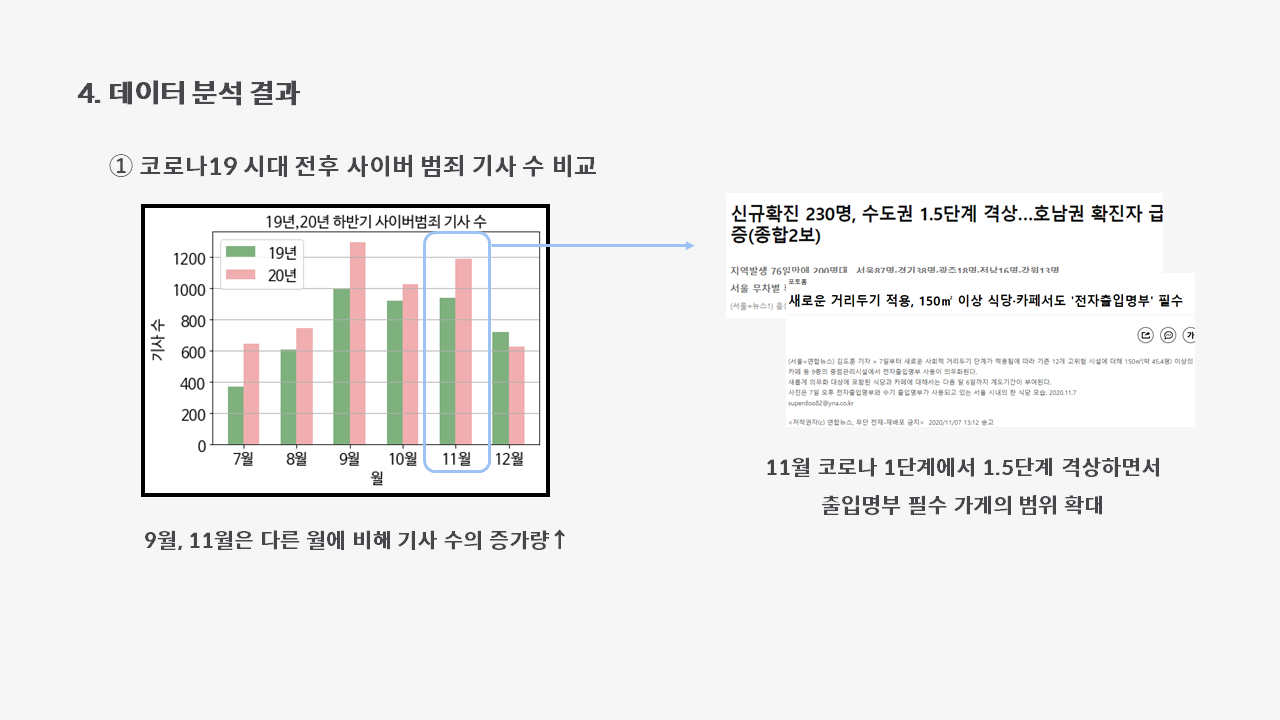
다음 11월의 경우, 집중방역기간을 지나 10월 12일부터 거리두기 1단계로 다시 완화되었지만, 곧 다시 1.5단계로 올라갔습니다. 그러면서 출입명부 필수인 가게의 범위가 늘어났는데, 이와 관련하여 개인정보 유출 관련 범죄가 늘어났고 그에 따라 사이버 범죄 피해량이 증가한 것으로 보입니다.
4-2. 코로나 확진자 수와 사이버 범죄 기사 수의 관계
이번에는 선 그래프와 막대 그래프로 코로나 확진자 수와 사이버 범죄 기사 수를 비교해보겠습니다~
코드는 다음과 같습니다!
plt.style.use('default')
plt.rcParams['figure.figsize'] = (4, 3)
plt.rcParams['font.size'] = 12
x = np.arange(7,13)
fig, ax1 = plt.subplots()
ax1.plot(x, df_a_b['확진자수/100'], '-s', color='royalblue', markersize=7, linewidth=5, alpha=0.7, label='corona')
ax1.set_ylim(0, 280)
ax1.set_xlabel('Month')
ax1.set_ylabel('Number of corona infected')
ax2 = ax1.twinx()
ax2.bar(x, df_a_b['기사제목'], color='#e35f62', label='articles', alpha=0.7, width=0.7)
ax2.set_ylim(500, 1500)
ax2.set_ylabel('Number of articles')
ax1.set_zorder(ax2.get_zorder() + 10)
ax1.patch.set_visible(False)
ax1.legend(loc='upper left')
ax2.legend(loc='upper right')
plt.show()
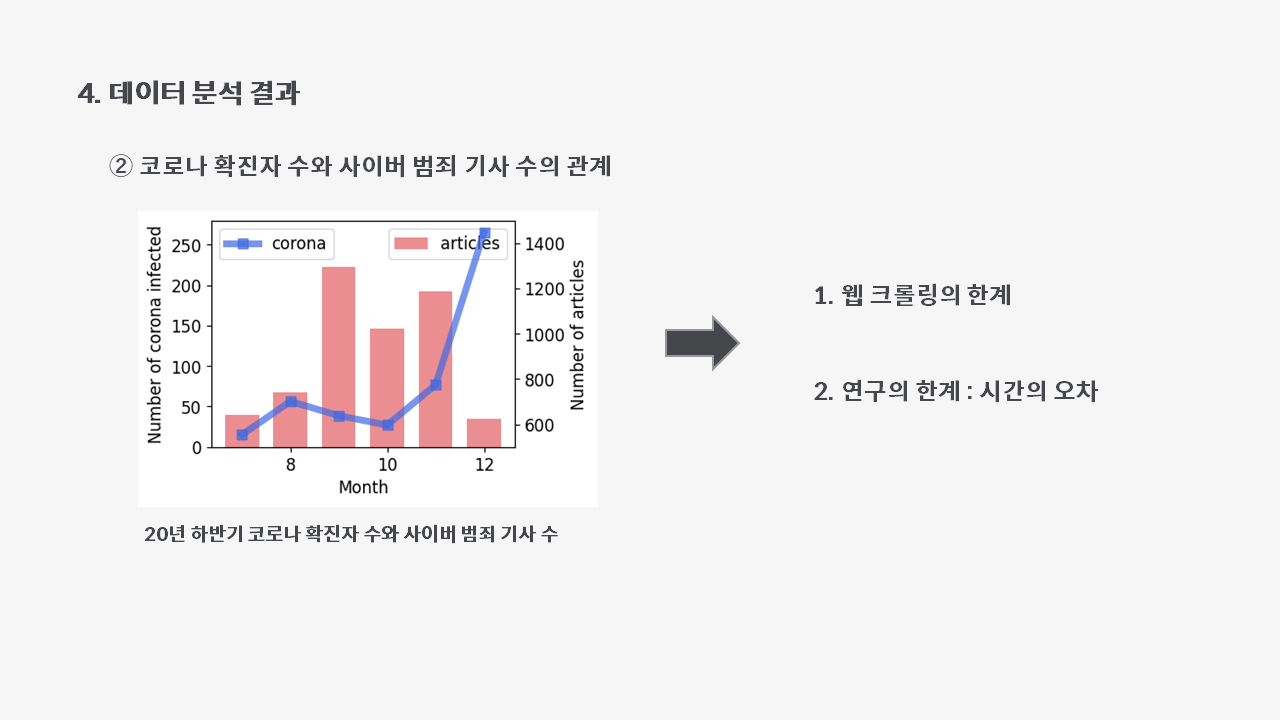
짜쟌!!!!!! 예쁘게 막대 그래프와 선그래프가 그려졌습니다~~~😆
파란 선그래프가 확진자 수를, 빨간 막대 그래프가 기사 수를 나타냅니다.
엇... 근데... 전혀 관련이 없어보이죠...🙄😒😥
그 이유를 생각해본 결과,
- 웹크롤링의 한계가 있다
키워드를 정해서 검색을 했음에도 불구하고, 범죄와는 연관성이 없는 기사가 함께 크롤링되서 분석 결과에 영향을 줄 수 있기 때문입니다. 2. 시간의 오차 때문이다. 코로나와 범죄율이 연관이 있다고 하더라도, 기사화 되기까지 시간이 필요하기 때문에 월별 시각화 상으로는 연관이 떨어질 수 있기 때문입니다.
야심 차게 비교해봤는데 기대한 결과가 나오지 않았네요😭😭😭
이렇게 예상할 수 없는 결과가 나올 수 있다는 점이 데이터 분석의 매력 아니겠어요?!!
힘내서 다음 분석을 해봅시다!!!😤😤😤
4-3. 19,20년 사이버 범죄 기사 키워드 비교
마지막으로 해볼 분석은 워드클라우드를 이용한 두 기간의 키워드 비교입니다.
#필요한 모듈 불러오기
from wordcloud import WordCloud, STOPWORDS
import numpy as np
import nltk
from PIL import Image
from konlpy.tag import Okt
okt = Okt()
#19년도 기사 제목 형태소 별로 분리
title_19 = ''
for each_line in df_19['기사제목']:
title_19 = title_19 + each_line + '\n'
tokens_19 = okt.morphs(title_19)
#19년도 키워드 중 불용어 제거
stop_words = ['\n',',',"'",'…','[',']','"','에','“','·','”','‘','’','의','명','도','은','이','...','로','한',
'으로','2','내년','나','건','-','그','등','657','중','더','가','만','개','제','3','사','하는','/','들',
'10','까지','할','만에','다','는','수','새','몸캠피','씽','시',"',",'디','및','피','(','무료','팀','’,',
'을','와','장','해','적','해야','?','과','아','피카','막아','하며',')','㈜','서','),','에서',")'",'액',
'통해','를','위','인','무','휴','퍼블','휴','화','한다','간','큐어','24시간',]
tokens_19 = [each_word for each_word in tokens_19 if each_word not in stop_words]
ko_19 = nltk.Text(tokens_19, name='19년도 기사제목')
#20년도 기사 제목 형태소 별로 분리
title_20 = ''
for each_line in df_20['기사제목']:
title_20 = title_20 + each_line + '\n'
tokens_20 = okt.morphs(title_20)
#20년도 키워드 중 불용어 제거
stop_words = ['\n',',',"'",'…','[',']','"','에','“','·','”','‘','’','의','명','도','은','이','...','로','한',
'으로','2','내년','나','건','-','그','등','657','중','더','가','만','개','제','3','사','하는','/','들',
'10','까지','할','만에','다','는','수','새','인','형','또','우리','銀','넘어','A','Z','번','해야','당','..','달','"…','4','에서','?…','!','장',
'첫','대','을','없다','이유','`','내','원','?','때','고','못','1','것','과','된','될','적','서','보위',
'성','한다','위','빅브','러더','된다','화','땐','’…','놈','하나','…"','선','>','안','연내','권','하면',
'(', ')','좀',"'…",'를','씽','피','시','라','및','풋','디','막은',"',",'액','확','아','퍼블','해','와','’,',
'간','’,','···','통해','몸캠피','큐어',]
tokens_20 = [each_word for each_word in tokens_20 if each_word not in stop_words]
ko_20 = nltk.Text(tokens_20, name='20년도 기사제목')
#19년도 워드클라우드
data = dict(ko_19.vocab().most_common(150))
wordcloud = WordCloud(font_path='/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf',
relative_scaling = 0.2,
background_color='white',).generate_from_frequencies(data)
plt.figure(figsize=(12,8))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
#20년도 워드클라우드
data = dict(ko_20.vocab().most_common(150))
wordcloud = WordCloud(font_path='/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf',
relative_scaling = 0.2,
background_color='white',).generate_from_frequencies(data)
plt.figure(figsize=(12,8))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
이렇게 코드를 쓰면,

이렇게 예쁜 워드 클라우드가 나옵니다🤩🤩🤩
둘의 차이가 보이시나요??
이제 눈에 띄게 증가한 키워드를 중심으로 같이 분석해볼까요?🙌
1. 코로나
코로나는 19년도에 존재하지 않았으니까 당연한 결과겠죠?

눈에 띄는 점은 ‘코로나’라는 키워드가 크롤링 수로 순위를 세웠을 때, 20등으로 꽤 높은 순위를 차지했다는 점입니다.
코로나19 확산으로 인한 PC, 스마트폰 이용량의 증가가 사이버 범죄에 영향을 주었을 것으로 보입니다.
2. 카카오, 메신저

두 키워드 모두 20년도에 새로 생긴 키워드입니다.
메신저를 이용하여 자녀 행세하며 부모님에게 금전을 요구하는 범죄가 증가하고 있다는데, 그 영향으로 보입니다.
3. AI

AI 기술이 발전하면서 문자 피싱을 넘어 AI를 이용한 피싱, 일명 딥 페이크 피싱이 늘어나는 추세라고 합니다.
이에 맞서 요즘 은행에서 "AI피싱 예방 시스템"을 만들고 있다고 합니다.
4. 개인정보
가장 자체 크롤링 수와 19년도와 비교 했을 때의 크롤링 증가 수가 많았던 키워드입니다.

식당, 카페의 출입명부 작성으로 개인정보 유출량이 증가하였고, 비대면 서비스가 많아지면서 개인정보를 온라인에 저장하거나, 온라인을 통해 제 삼자에게 공개하는 일이 많아지면서 개인정보 관련 범죄가 많아진 것으로 보입니다.
5. 결론

이렇게 코로나19와 사이버범죄 간의 연관성에 대해 분석해본 결과, 코로나 19 시대로 오면서 사이버 범죄가 증가한 것은 확실히 맞다는 것을 알 수 있었습니다.
그 원인으로 비대면 기술의 급격한 발전, 비대면 서비스의 증가 등이 있었지만, 이를 단순하게 코로나 확진자 수와 연관지어 분석하기에는 어려움이 있다는 것도 알게 되었습니다.
마지막으로 워드클라우드 분석 결과, 코로나, 메신저, 카카오, AI, 개인정보라는 키워드가 눈에 띄었고, 이러한 키워드들이 어떠한 의미를 갖고 있는지에 대해 알아보았습니다.
참고 자료
- 사단법인한국산업보안연구학회, “산업보안학”, ㈜박영사(2019)
- http://m.joseilbo.com/news/view.htm?newsid=395618#_enliple
- https://news.nate.com/view/20210407n07705http://www.hnews.co.kr/news/articleView.html?idxno=54570
- http://www.newstomato.com/ReadNews.aspx?no=1022842https://www.edaily.co.kr/news/read?newsId=01279206625642968
- https://www.ytn.co.kr/_ln/0115_202012231351487525